RFC: patch manifests (editing via web UI)
(1.1) By Stephan Beal (stephan) on 2020-04-26 15:56:12 edited from 1.0 [link] [source]
One of the most-requested feature in Fossil's history has been the ability to edit files online. On the surface, it seems like a reasonable thing to do, the main hurdle being that generation of the resulting manifest requires a checkout.
The rest of this post proposes a new type of manifest, tentatively called a patch manifest, which may enable us to add this feature without a significant overhaul of how manifests are generated. Comments and suggestions are encouraged.
Management summary: a patch manifest is essentially a type of delta manifest in which at least one file and any number of tags are modified (which includes adding or removing them). This feature is targeted specifically at the web interface, but it could hypothetically be used for any single-file commits, as a manifest generation optimization.
A patch manifest (PM) is semantically similar to a Delta Manifest, with the exception that a PM's baseline and parent are always the same. Where a delta manifest can be a delta of any version while having a different version as its parent, a PM cannot.
Hypothetically a PM could use a "B" card to specify its source version, but that would leave us unable(?) to unambiguously distinguish a delta manifest from a PM, and thus a PM uses a new card to specify the origin/baseline version:
< PARENT_VERSION_UUID
A PM must/may have the following cards:
<a single parent manifest version- C checkin-comment
- D time-and-date-stamp
- F filename ?hash? ?permissions? ?old-name?
Typically only one, but there's no(?) reason the format cannot support more. - N mimetype of the C-card (optional)
- R repository-checksum (optional)
- T (+|-|*)tag-name * ?value? (optional)
- U user-login
- Z manifest-checksum
Semantic differences from a normal manifest or delta manifest include:
- F-card: A PM must have at least one F-card. If an F-card has no arguments after the name, that file is removed by this checkin. Optionally, a PM could support only editing, and not addition or removal (but it seems likely that those would become requested features).
- P-card: only a single parent is permitted, as having multiple parents would not be practical via web-based editing.
- No Q-cards (cherry-pick).
- R-card: whether or not it's really feasible to generate an R-card for this case is not yet clear. R-cards introduce a significant CPU/memory load which might not be realistic for all server-side environments.
The version's complete set of F-cards is the parent's list of F-cards modified by the PM's list (add/remove/edit), and thus the name "patch manifest." Tag changes are handled exactly as they are for standard manifests.
The web-UI workflow for creation of PMs would look something like:
- Select a file to edit.
- Edit it. Depending on the mimetype, a preview mode might or might not be available. (Embedded docs, yes. C code, no.)
- Save/upload the file, which generates the PM and crosslinks the manifest (thereby updating the timeline).
Potential issues:
- Editing a file online requires editing from a specific repo version. It's possible that another user has committed between the start of editing and saving of a file, leading to a fork. This post assumes that forks are simply an unavoidable eventuality, that "unintended forks" are created as needed (without prompting), and that resolving them requires checkout-level access. Resolving forks via a web interface is considered to be far outside of this proposal's scope.
- Similarly, merging is considered out of scope. Branching, on the other hand, could easily be supported.
- Obviously, any new artifact type is inherently non-backwards-compatible.
Does this sound reasonable and/or realistic? Have i overlooked anything? What aspects can be improved?
(2) By Florian Balmer (florian.balmer) on 2020-04-27 07:24:53 in reply to 1.1 [link] [source]
Thoughts:
Can't the same be achieved with usual delta manifests, so as not to sacrifice backwards compatibility? The check-ins could have a tag or comment prefix automatically applied to mark them as "web edits".
Instead of "preview", what about "preview diff", similar to the skin editor?
Not sure if web browsers will send back the original line endings (CR/LF) for unchanged text, and use consistent line endings for new/edited text, so this may require special attention.
I can see some benefit from "web edits" -- but on the other hand, quick pull/push changes are already super-easy with Fossil, and with a proper text editor instead of a rudimentary textarea. And it's indeed a shift away from the "no forks" and "no untested commits" policies often advocated here.
(3) By Stephan Beal (stephan) on 2020-04-27 08:51:52 in reply to 2 [link] [source]
Can't the same be achieved with usual delta manifests
i've actually been wondering the same thing, but have not yet looked into in more detail. That would have one drawback, though: a delta manifest must derive from a baseline manifest. We cannot chain deltas together. A patch manifest could hypothetically be chained. Thus if we create a delta manifest from version X, then want to create another patch, the baseline must be X, but the new patch would need to include its own changes and those from the preceding delta manifest(s).
Instead of "preview", what about "preview diff", similar to the skin editor?
There's no reason we can't do both, really. For embedded docs (my only primary use case), a diff is less interesting to me than a preview, but when editing code, which has no preview mode, a diff would indeed be nice.
Not sure if web browsers will send back the original line endings (CR/LF) for unchanged text, and use consistent line endings for new/edited text, so this may require special attention.
That's a very good point. When generating the form, we could add a hidden form field which specifies which line-feed type the file has, and make sure we convert (if necessary) back to that when saving the result.
I can see some benefit from "web edits" -- but on the other hand, quick pull/push changes are already super-easy with Fossil, and with a proper text editor instead of a rudimentary textarea.
Agreed 100%, but it has always been an oft-requested feature and i have often wanted to make a quick edit to embedded docs from my tablet. The one advantage of the wiki over embedded docs is that capability.
And it's indeed a shift away from the "no forks" and "no untested commits" policies often advocated here.
"No forks" is only strongly advocated by gitites (is that the correct term? gits? gitians? gitters?). "fork" is not a "bad word" in fossil parlance like it is in git.
"No untested commits" doesn't really apply to doc commits. Anyone who breaks their own tree by checking in broken code has only themselves to blame. (And if they do it in the main fossil tree there will be... Ärger.)
Perhaps we may want an extra "web commit" permission for this.
(4) By Florian Balmer (florian.balmer) on 2020-04-27 12:10:23 in reply to 3 [link] [source]
So delta manifests are more work to generate, but patch manifests are more work to parse and crosslink (the same steps, just in reverse order)? Given the recent discussions on LTS and Fossil versions in packages/distros, the first variant to preserve backwards compatibility seems less invasive, somehow.
(5) By Stephan Beal (stephan) on 2020-04-27 12:32:39 in reply to 4 [link] [source]
So delta manifests are more work to generate, but patch manifests are more work to parse and crosslink (the same steps, just in reverse order)?
i think a PM and delta would have approximately the same parsing and cross-linking performance (crosslinking requires parsing, but there are other reasons to parse manifests aside from crosslinking). A delta is computationally a bit more expensive to generate than a baseline manifest, but is normally much, much smaller.
Interestingly, fossil's core repo doesn't appear (at a quick glance) to have delta manifests, but in one of my repos, the two previous checkins are deltas generated from a common baseline which is actually 21(!) commits earlier. That commit's manifest is 454 lines and the current tip is 37 lines.
Sidebar: Fossil doesn't generate delta manifests by default unless it has seen at least one of them in the repo in the past. Using commit --delta will force generation of a delta manifest and implicitly tells fossil that it's okay to create deltas in the future (it sets repo.config seen-delta-manifest to 1).
But what i really came here to say was...
Now i recall why i didn't initially consider delta manifests: constructing one requires a checkout, whereas a patch manifest is trivial enough that it could be generated without a checkout.
On the other hand, if we can bend the manifest-generation bits so that they can work from either a checkout or directly from the repo, the concept of a patch manifest becomes almost irrelevant (except that it might still be an interesting space optimization, as it only includes a single F-card). Unless i'm sorely mistaken, the only real hindrance to implementing online editing is the manifest generation being tied to the checkout. i cannot say off-hand how closely they are connected, though - it might be trivial matter to resolve.
(6) By Stephan Beal (stephan) on 2020-04-27 13:12:16 in reply to 5 [link] [source]
On the other hand, if we can bend the manifest-generation bits so that they can work from either a checkout or directly from the repo, the concept of a patch manifest becomes almost irrelevant (except that it might still be an interesting space optimization, as it only includes a single F-card). Unless i'm sorely mistaken, the only real hindrance to implementing online editing is the manifest generation being tied to the checkout. i cannot say off-hand how closely they are connected, though - it might be trivial matter to resolve.
Follow-up...
The checkin process is very closely tied to the checkout db and files. Generation of the manifest itself (whether it's a baseline or delta) requires access to vfile (checkout db) to get the list of "selected" files. It "might" be feasible, for purposes of a single-file web commit, to create a fake/temp vfile which includes the contents from the parent checkout and has the being-saved content marked as "selected".
While the checkin command is highly detailed and complex (just over 600 lines), a patch manifest could probably be generated in maybe 1/5th as much code. Reading over the checkin code, the main differences would be:
- Generation of the raw manifest is much simpler.
- Generation of the R-card is easy in both cases, but the PM could not perform the 2nd R-card step: compare the R-card (generated from the repo) to the same data in the filesystem, as the filesystem (checkout) isn't there.
- Skip possible generation of a delta manifest.
- Forking would be enabled, whereas checkin tries to avoid it. Web-based error handling and recovery for the "do you really want to fork?" case adds lots of complexity, including keeping the to-be-committed content intact across multiple requests. Similarly, checking in to a closed leaf should arguably be enabled for a PM, re-opening the closed leaf when that happens.
- No interactive comment editing. The comment would be submitted along with the editor form.
- No merge handling - fork instead.
- Permissions handling would need to change, since web content has no permissions: inherit the +x permissions from the previous version of the being-committed file.
- vfile table handling (i.e. checkout db) disappears.
It looks like such a "reduced-functionality" checkin subset is feasible with delta manifests, as opposed to a new manifest type. That's an interesting rabbit hole for me to climb down, hopefully soon.
(12) By anonymous on 2020-04-28 06:25:54 in reply to 3 [link] [source]
if we create a delta manifest from version X, then want to create another patch, the baseline must be X
If we are a committing a change to a file in version Y, which is a delta based on X, we already know that Y is based on X, so we know to create delta manifest Z based on version X.
Seems to me, whether the change originates from a checkout or a web submission, creating a delta against a known base version is the same when the base isn't the current checkout version.
"No forks" is only strongly advocated by gitites
Forks still cause problems. Yes, it's easy enough to use fossil leaves -m to find them, but that's an extra step. Why not make the check automatic after any pull operation, not just during a commit with auto-sync turned on?
Anyone who breaks their own tree by checking in broken code has only themselves to blame.
While true, the consequences of the "broken commit" all too often fall on the other team members in the project.
Despite my dislike for untested commits, in some situations, they are justifiable.
Perhaps we may want an extra "web commit" permission for this.
I think this would be a very good thing to include.
(13) By Stephan Beal (stephan) on 2020-04-28 07:48:16 in reply to 12 [link] [source]
If we are a committing a change to a file in version Y, which is a delta based on X, we already know that Y is based on X, so we know to create delta manifest Z based on version X.
That's true, and i didn't realize until later that when we have Y in hand then we already know its baseline (X), so we know which baseline to use for Z. The complication in generating delta manifests is that in that scenario, version Z has to be based on X, as you say, but also has to include the changes from prior deltas based on X (in this case, that's version Y). If delta manifest Z doesn't include delta manifest Y's changes then Y's changes effectively get lost when Z is created.
Unfortunately, the code which does that work (checkin.c::create_manifest()) is closely tied to the vfile and vmerge tables (both part of the checkout), so we can't yet use it in this feature. i think i can fake my way around that by creating a temp vfile table populated with the info for our current version, plus the new commit, and an empty temp vmerge table, but that experimentation will wait until after the feature is more or less feature-complete.
Forks still cause problems. Yes, it's easy enough to use fossil leaves -m to find them, but that's an extra step. Why not make the check automatic after any pull operation, not just during a commit with auto-sync turned on?
Forks aren't "wrong", per se (that's a myth propagated by gitites). The data model supports them and there are valid reasons for wanting to have them. If we warn a user after every pull that they have at least one fork, we're going to introduce unsightly noise for every repo which knowingly/legitimately has forks (and we'd thereby implicitly further propagate the myth that "forks are bad"). Warning about them only at commit-time ensures that we're only emitting noise at the point where they're created. For some users it's not a concern and they can ignore it. My understanding (possibly incorrect) is that we also don't know, aside from during the commit process, whether a fork was unintentional/accidental when examining the history later on.
While true, the consequences of the "broken commit" all too often fall on the other team members in the project.
The consequences can affect any number of people, but the guilty party is the person who checked it in, not the software which enabled that checkin. Anyone can check in broken code via a checkout (who, me?!?), so this problem is not specific to this new feature. The new feature, if not used responsibly, just makes it easier to do so.
Sidebar (mostly to verify to myself that the first paragraph above is not a complete lie)... as an example of deltas containing the changes from each previous delta, here's a session from my single most active repo, where the top 20 or so commits are deltas from a common baseline. If we look at each one, starting from the top, we see that each new one has one more line than its predecessor (indicating that these were single-file checkins):
$ f time -n 3
=== 2020-04-24 ===
12:09:34 [6552458a35] ...
11:23:23 [98ad1bee7f] ...
11:18:48 [c13e4296b3] ...
...
# Get the card count, parent, and baseline for each of those, from
# newest to oldest:
$ v=trunk; f artifact $v | wc -l; f artifact $v | grep -e '^P ' -e '^B '
37
B c46a39fd75066002fc82a438a1b978d9cbe1a0e9
P 98ad1bee7fe31fafbc4954ac8325e3910f70df85
$ v=98ad1bee7fe31fafbc4954ac8325e3910f70df85; f artifact $v | wc -l; f artifact $v | grep -e '^P ' -e '^B '
36
B c46a39fd75066002fc82a438a1b978d9cbe1a0e9
P c13e4296b3bd4230948ce69863a8b6f644c6d30c
$ v=c13e4296b3bd4230948ce69863a8b6f644c6d30c; f artifact $v | wc -l; f artifact $v | grep -e '^P ' -e '^B '
35
B c46a39fd75066002fc82a438a1b978d9cbe1a0e9
P 0d30ade8a6face16bf47c0dfafd4878cce8947ad
And to confirm that the F-cards account for the line count difference:
$ v=trunk; f artifact $v | grep -c -e '^F '
30
$ v=98ad1bee7fe31fafbc4954ac8325e3910f70df85; f artifact $v | grep -c -e '^F '
29
$ v=c13e4296b3bd4230948ce69863a8b6f644c6d30c; f artifact $v | grep -c -e '^F '
28
# Baseline has...
$ v=c46a39fd75066002fc82a438a1b978d9cbe1a0e9; f artifact $v | grep -c -e '^F '
448
(23) By anonymous on 2020-04-29 11:49:00 in reply to 13 [link] [source]
but also has to include the changes from prior deltas based on X (in this case, that's version Y)
Couldn't that be accomplished by copying manifest Y to manifest Z, then adding or replacing the entry for the file being edited?
(24) By Stephan Beal (stephan) on 2020-04-29 11:58:52 in reply to 23 [link] [source]
Couldn't that be accomplished by copying manifest Y to manifest Z, then adding or replacing the entry for the file being edited?
That is an interesting idea. The way a manifest is created doesn't readily support that, but it's worth experimenting with. It sounds feasible, at least. My only initial concern is that Y having merge parents might be a problem, but that may just be my inherent "cautious pessimism" speaking.
Thank you for the idea.
(25) By anonymous on 2020-04-29 12:31:59 in reply to 24 [link] [source]
My only initial concern is that Y having merge parents might be a problem
I was glossing over some details, like, for example, setting the parent of Z to be Y. Since this would not be a merge commit, the P card could be completely replaced by one that designates Y as the parent. Also, any Q cards could be discarded (or not copied).
Admittedly, I had not thought about the possibility that a merge manifest could be a delta manifest.
(27) By Stephan Beal (stephan) on 2020-04-29 12:41:32 in reply to 25 [link] [source]
Admittedly, I had not thought about the possibility that a merge manifest could be a delta manifest.
i don't know for sure that it can, but it's worth looking into before breaking something. Indeed, Q-cards would simply be discarded - they don't propagate. In any case, it's a very interesting idea and is on my list of things to try.
(26) By Stephan Beal (stephan) on 2020-04-29 12:37:55 in reply to 2 [link] [source]
Not sure if web browsers will send back the original line endings (CR/LF) for unchanged text, and use consistent line endings for new/edited text, so this may require special attention.
Follow-up: HTML5 indeed specifies this to use Windows-style line-endings.
https://html.spec.whatwg.org/multipage/form-elements.html#the-textarea-element
The relevant section is (emphasis added by me):
For historical reasons, the [TEXTAREA] element's value is normalized in three different ways for three different purposes. The raw value is the value as it was originally set. It is not normalized. The API value is the value used in the value IDL attribute, textLength IDL attribute, and by the maxlength and minlength content attributes. It is normalized so that line breaks use U+000A LINE FEED (LF) characters. Finally, there is the value, as used in form submission and other processing models in this specification. It is normalized so that line breaks use U+000D CARRIAGE RETURN U+000A LINE FEED (CRLF) character pairs, and in addition, if necessary given the element's wrap attribute, additional line breaks are inserted to wrap the text at the given width.
Curiously, they define newline normalization of a string the opposite:
https://infra.spec.whatwg.org/#normalize-newlines
To normalize newlines in a string, replace every U+000D CR U+000A LF code point pair with a single U+000A LF code point, and then replace every remaining U+000D CR code point with a U+000A LF code point.
It looks like that's the next feature to implement before adding the web interface.
(7) By Richard Hipp (drh) on 2020-04-27 13:42:05 in reply to 1.1 [link] [source]
generation of the resulting manifest requires a checkout.
Seems like it would not be difficult to add code that constructs a manifest given:
- The parent manifest
- The name and new hash of the one file that changed
- A check-in comment
- A timestamp (or just use the current time?)
- Any tags needed for the new check-in (such as if it is changing branches. This is usually an empty set, I suppose.)
- The name of the user who is making the change
Am I overlooking some complication? Why do we need a checkout?
(8) By Stephan Beal (stephan) on 2020-04-27 14:04:25 in reply to 7 [link] [source]
Seems like it would not be difficult to add code that constructs a manifest given:
...
Am I overlooking some complication?
IMO, no - that's essentially all we'd seemingly need.
The checkin process is heavily dependent on vfile and the filesystem contents, but this hypothetical new feature would be a subset of checkin which needn't have those dependencies. The only hurdle of note i currently see is that the common underlying bit - create_manifest() - requires vfile because that's how it gets its selected file list. If that vfile dependency can be bypassed, e.g. via injecting a temp table named vfile which holds only the columns/state needed by this hypothetical feature, or via some new data structure holding that state, then it sounds easy peasy.
Creating the R card is, it turns out, not problematic, but we cannot, without a checkout, confirm that the R-card matches what was read, so whether or not to compute one in the first place seems questionable.
Creating a prototype which works from the CLI doesn't seem like it would be a big deal, so that's on my short-term TODO list.
(9) By ramsan on 2020-04-27 14:19:58 in reply to 8 [link] [source]
Wouldn't it be possible, with this new technology, implement easily what was discussed here:?
(10) By Stephan Beal (stephan) on 2020-04-27 14:42:01 in reply to 9 [link] [source]
Wouldn't it be possible, with this new technology, implement easily what was discussed here:?
In a much more limited form. Creating a web interface which can manage edits to multiple files at a time and extending the backend to accept multi-file uploads are out of scope. Initially (and maybe permanently), the scope is only to handle edits of a single already-existing file. Adding, removing, and renaming files is currently out of scope, but those could perhaps be added after the most basic features are in place. (No promises, though.) This feature is intended to be a fallback for basic editing when a checkout is not available, and is in no way intended to replace any other functionality which currently requires a checkout.
(11.2) By Stephan Beal (stephan) on 2020-04-27 19:18:25 edited from 11.1 in reply to 7 [link] [source]
Proof of concept in about 250 lines of code (including docs):
(Notes follow the demo.)
# Intentional error, ensuring that we disallow adding new files:
[stephan@lapdog:~/fossil]$ f test-ci-web -R webci.fsl webci/README.md --as readme.md -m "Without a checkout."
File [readme.md] not found in manifest. Adding new files is currently not allowed.
# Noting that that's an artificial limitation: it "would work" if that check
# were removed, but first we need to confirm that the input path is properly
# normalized and relative to the top of the tree.
# Dry-run:
$ f test-ci-web -R webci.fsl webci/README.md --as README.md -m "Without a checkout."
Manifest:
C Without\sa\scheckout.
D 2020-04-27T18:34:23.261
F README.md 0e725a5806b0a5a1264ec8e5234b2e9fff6f523c52a223f702e4d1e57b8518ed
P dbb3484349d13368dbefa64107afb86f7e92fd8cf46648ae744f7aa5e13adb4c
U stephan
Z 86cd57af9ade9e96040e2e8b36775000
Rolling back transaction.
# Not a dry run:
$ f test-ci-web -R webci.fsl webci/README.md --as README.md -m "Without a checkout." --wet-run
Manifest:
C Without\sa\scheckout.
D 2020-04-27T18:34:29.094
F README.md 0e725a5806b0a5a1264ec8e5234b2e9fff6f523c52a223f702e4d1e57b8518ed
P dbb3484349d13368dbefa64107afb86f7e92fd8cf46648ae744f7aa5e13adb4c
U stephan
Z afbcf8c11236727e9d782a9adce654a0
# Did it work?
$ f timeline -R webci.fsl -n 2
=== 2020-04-27 ===
18:34:29 [9789dda195] Without a checkout. (user: stephan tags: trunk)
18:29:30 [dbb3484349] Nth attempt. (user: stephan tags: trunk)
$ f artifact -R webci.fsl 9789dda195
C Without\sa\scheckout.
D 2020-04-27T18:34:29.094
F README.md 0e725a5806b0a5a1264ec8e5234b2e9fff6f523c52a223f702e4d1e57b8518ed
P dbb3484349d13368dbefa64107afb86f7e92fd8cf46648ae744f7aa5e13adb4c
U stephan
Z afbcf8c11236727e9d782a9adce654a0
# Diff?
$ f dif -R webci.fsl --from dbb3484349 --to 9789dda195
Index: README.md
==================================================================
--- README.md
+++ README.md
@@ -22,5 +22,7 @@
(Mon Apr 27 20:08:30 CEST 2020)
-----
(Mon Apr 27 20:09:48 CEST 2020)
-----
(Mon Apr 27 20:29:25 CEST 2020)
+-----
+(Mon Apr 27 20:33:33 CEST 2020)
It works from within a checkout dir as well, but that leaves the checkout db out of sync with regards to these changes:
This time from a checkout dir...
$ echo -e "-----\n($(date))" >> README.md
$ f test-ci-web README.md -m "From a checkout." --wet-run
Manifest:
C From\sa\scheckout.
D 2020-04-27T18:43:30.266
F README.md a30d42f0c8032738d511bf4f554031bfca9e4a36986a7c7dc6bb0111e3374890
P 9789dda1959ccdcac8b27c0e7cda5348dfc2de1a798aa28583b0b067aa519739
U stephan
Z 737ed07b997bb60cff4bc6d29c983709
The checkout state is now out of sync with regards to this commit. It needs to be 'update'd or 'close'd and re-'open'ed.
$ f cha
EDITED README.md
$ f up
MERGE README.md
-------------------------------------------------------------------------------
updated-to: 99955b35cf69882b6f47fe12efe9245432c341d8 2020-04-27 18:43:30 UTC
tags: trunk
comment: From a checkout. (user: stephan)
changes: 1 file modified.
"fossil undo" is available to undo changes to the working checkout.
$ f cha
<no output>
$ f time -n 3
=== 2020-04-27 ===
18:43:30 [99955b35cf] *CURRENT* From a checkout. (user: stephan tags: trunk)
18:34:29 [9789dda195] Without a checkout. (user: stephan tags: trunk)
18:29:30 [dbb3484349] Nth attempt. (user: stephan tags: trunk)
--- entry limit (3) reached ---
Points of potential interest:
It currently ignores the line endings and stores the content it is given as-is. That is not an issue when working from files but will, as Florian pointed out, be a potential issue when committing from an HTML form. We'll need to, when serving the editor field, store the detected newline style, then reapply it, if needed, when saving.
It does not yet attempt to create a delta manifest, but i would strongly prefer to generate deltas, so that's on my TODO list. (It's not yet clear to me how to find a baseline to work from.) That said: fossil's core repo does not use deltas, and i have to assume there's a reason for that. Once a single delta manifest is injected, any number of future commits may be deltas.
It does deltify the file's content against the previous version.
File permissions are inherited from the file's previous version. If a file has the "l" permission (is a symlink) then it fails loudly. There would seem to be no sensible way to handle symlinks here, so they're simply disallowed. If a new file is added, it is assumed to be a normal/non-exe file.
Edit:
Ooops: i intended to add the R-card but apparently forgot. Its utility is in question in this use case, anyway, because it's normally checked against the filesystem between the time the content is stuffed into the db and the time of the commit (and it's not checked at any other time, AFAIK). Computing the R-card and simply storing it bypasses that check, which seemingly makes the R-card useless for any future purposes.
Nevermind: the R-card calculation is currently done via vfile, which we don't have in this context, so we'd instead need to calculate it manually as we build the manifest. So...
Is adding the R-card worth the effort, seeing that we cannot verify it in the usual sense? Is there another way to make use of the R-card, or is it meaningless except at checkin-time from within a local checkout?
(14.2) By Stephan Beal (stephan) on 2020-04-28 16:09:04 edited from 14.1 in reply to 1.1 [link] [source]
Follow-up and RFC about next steps...
$ f help test-ci-one
Usage: f ?OPTIONS? FILENAME
where FILENAME is a repo-relative name as it would appear in the
vfile table.
Options:
--repository|-R REPO The repository file to commit to.
--as FILENAME The repository-side name of the input file,
relative to the top of the repository.
Default is the same as the input file name.
--comment|-m COMMENT Required checkin comment.
--comment-file|-M FILE Reads checkin comment from the given file.
--revision|-r VERSION Commit from this version. Default is
the checkout version (if available) or
trunk (if used without a checkout).
--wet-run Disables the default dry-run mode.
--allow-fork Allows the commit to be made against a
non-leaf parent. Note that no autosync
is performed beforehand.
--user-override USER USER to use instead of the current default.
--date-override DATETIME DATE to use instead of 'now'.
--dump-manifest|-d Dumps the generated manifest to stdout.
Example:
f test-ci-one -R REPO -m ... -r foo --as src/myfile.c myfile.c
This is not intended for the pending 2.11 release, but i would like to discuss how/whether we want to move forward with this...
At this point the whole thing is just proof-of-concept and my feelings won't be hurt if we decide to drop it. However, it does provide us with an interesting feature which we don't currently have: the ability to commit individual files directly to a repository db without a checkout. For sanity's sake it currently disables adding of new files, but that's an artificial limitation intended primarily to help minimize "oopses" caused by typos or incorrect name case. Similarly, it offers no way to remove files. It is in no way intended to scope-creep to the point of being a general-purpose alternative for having a checkout. (If we add this, some amount of defending it against scope creep via feature requests is to be expected.)
Next Steps...
Assuming this is something worth pursuing..
Command Name?
Ostensibly, this feature is a subset of the checkin command and belongs in checkin, but in terms of implementation and options/CLI flags, it's a very different beast. That argues for one of two options:
If
checkinis called from outside of a repo, delegate it to the routine, else behave as normal. That would mean these features are not available from inside a checkin, but that's okay because these are a subset of checkin features.Add a separate command.
Combining them into a single implementation seems like madness, given the relative complexity of the two and checkin's dependency on vfile/vmerge, which would have to be if'd away when running in this mode. The complexity impact alone is a compelling reason not to merge the two into a single command. Delegation via checkin, though, would be low-impact and easy to do.
IMO, the only(?) halfway compelling reason to choose (2) over (1) is the help text. checkin's help is 90 lines long and would need another 20-odd for this command's current help (which is expected to grow as it matures).
Web Interface
The infrastructure has been created with both a CLI and web interface in mind, and the creation of the web-based equivalent of test-ci-one would be straightforward (as would moving test-ci-one to a delegate of checkin). However, before investing any time on a web interface we need to decide whether this is worth developing (noting that the onus of creating the web interface initially lies with me).
Misc. TODOs...
In no particular order...
- Move it from a local private branch to a public remote one.
- After vetting it fully, make "wet run" the default mode and add in
--dry-runflag. - Perhaps permit adding of new files, but this requires performing more validation/normalization on the input file name resp. the
--as NAMEflag. - Perhaps add a flag which tells it to
pullbefore the commit, to help avoid unintended forks. - Create delta manifests.
- Naming: what do we call this feature?
- Test the bejesus out of it.
Edit:
- A new permission for online editing sounds like a good idea to me. Whether or not it should be inherited (like most perms) or not (like
y(write unversioned)) is debatable. - Screenshot of the consequences of testing, noting that the branch was not created by this code. It doesn't apply tags or create branches - there are other interfaces for those features already.
{kind=link}
(15) By Florian Balmer (florian.balmer) on 2020-04-28 12:24:09 in reply to 14.1 [link] [source]
I think a different command with a different name is preferred, since running the same command in different contexts with different sets of available options seems confusing (at least to me ☺).
And, allow me to mention this early during your development efforts:
If a feature is "questionable" regarding core feature set vs. feature creep vs. security vs. simplicity, why not put it behind some #IFDEFs, so people who don't want it can disable is (since the feature might make it somewhat easier to sneak unwanted contents into a repository on a server, for example).
(18) By Stephan Beal (stephan) on 2020-04-28 12:56:31 in reply to 15 [link] [source]
An ifdef is something i hadn't considered. i don't consider this feature to be questionable/complex/insecure, though. It's often been requested over the years but we simply didn't have the infrastructure for it. Locking it behind an ifdef would make in unavailable to anyone who won't/can't build their own (which probably includes at least one person who's requested this feature).
The one arguably questionable aspect is that it does not generate an R-card. Those are optional in manifests because they're so expensive to compute, so it's not a tragic loss, but it is a noteworthy difference from commit.
As far as whether it belongs in commit or as a new command, i don't have a strong opinion. It semantically fits 100% with commit, but it has different requirements and CLI flags, so it could definitely be a bit confusing if they were combined.
(16) By ramsan on 2020-04-28 12:35:11 in reply to 14.1 [link] [source]
In my opinion, the most natural command would be:
fossil commit -m "my message" FILE1 FILE2 -R myrepository.fossil
command "commit" clearly expresses intent and -R clearly expresses that the commit is to be performed on a not-checked-out repository.
(17) By Stephan Beal (stephan) on 2020-04-28 12:51:20 in reply to 16 [link] [source]
fossil commit -m "my message" FILE1 FILE2 -R myrepository.fossil
Keep in mind, though, that it cannot/will not do multiple files because:
It was conceived to use primarily from a web interface, and handling multiple files that way would be extremely onerous.
In the CLI we have no intuitive way of mapping multiple input files to repo file names unless the input filenames are exactly as they are in the repo. If a user has multiple files with the exact same names/paths as in their repo then they can/should use a checkout or commit the files one at a time.
(19) By ramsan on 2020-04-28 17:15:36 in reply to 17 [link] [source]
- It was conceived to use primarily from a web interface, and handling multiple files that way would be extremely onerous.
Why? What's the difference?
- In the CLI we have no intuitive way of mapping multiple input files to repo file names unless the input filenames are exactly as they are in the repo. If a user has multiple files with the exact same names/paths as in their repo then they can/should use a checkout or commit the files one at a time
I do no see the reason.
- Option a)
mkdir src
cp FILE1 FILE2 src
fossil commit src/FILE1 src/FILE2 -R REPO.fossil
- Option b)
fossil commit FILE1 -as src/FILE1 FILE2 -as src/FILE2 -R REPO.fossil
- Option c)
fossil commit FILE1 -as src/FILE1 -R REPO.fossil
fossil commit FILE1 -as src/FILE2 -R REPO.fossil
I can understand to use option c) if it is too annoying to implement option b). However, I see option a) as perfectly natural and useful. Specially if you have a repository with 1000's of files and you want to modify only a few of them.
(20) By Stephan Beal (stephan) on 2020-04-28 17:55:19 in reply to 19 [link] [source]
It was conceived to use primarily from a web interface, and handling multiple files that way would be extremely onerous.
Why? What's the difference?
For starters, the UI would have to accommodate editing multiple files, holding a copy of each in memory as you browse the site and select/edit files. That only works on one-page apps, which fossil is not. Such an app would necessarily be heavily JS-centric, which is an anti-goal of fossil.
How fossil's core reacts to POST data would need to change to be able to accept so-called multi-part form data and store each part (file) separately so that downstream code could consume it appropriately. Then every bit of fossil which internally consumes POST data would need to be modified to account for the new structure. That's not going to happen in the scope of adding this feature.
I do no see the reason.
fossil commit src/FILE1 src/FILE2 -R REPO.fossil
If a user has files laid out in the exact same structure as a checkout then they can just as easily use a full checkout. This feature IS NOT intended to replace a checkout for generic use (nor will that ever be a goal). It's intended to provide the basis of editing files online. The fact that it works locally at all is just "bonus points" - a happy side effect. One restriction of an online implementation, given our existing UI and back-end, is that it only accepts a single file. Thus the CLI variant, which uses the same infrastructure, also only accepts a single file.
fossil commit FILE1 -as src/FILE1 FILE2 -as src/FILE2 -R REPO.fossil
If it were that easy, that would already have been done. Fossil's core CLI argument handling doesn't give us an easy way to do that. The command would have to duplicate much of what fossil's lower-level argument-handling functions do. It "would be possible" but it would add a bunch of Ugly to the code. If that ever happens, it will be because someone else implements it or because i had entirely too much to drink.
I can understand to use option c) if it is too annoying to implement option b). However, I see option a) as perfectly natural and useful.
(A) is not an option i will entertain, plain and simple: for that type of usage, a user can use a checkout. This feature is not about replacing/eliminating a checkout, nor is that capability required for web-based edits. Keep in mind that no(?) SCM allows users to modify files without a checkout. It's simply not part of the SCM usage model.
(B) would require bypassing and reimplementing bits of fossil's core. It would be possible but painful to implement.
(C) is the only easily-implementable option using the current infrastructure.
Once (C) is in place, we can look at enhancing it, but the "first version" is not going to attempt to build a whole rocket ship in one go.
(22) By anonymous on 2020-04-29 09:31:11 in reply to 20 [link] [source]
I am starting to use Fossil for all sorts of stuff myself and what would be great is if in future there can be a option to create the repository and check in the file with it's last edit date, both in this one command...
A few days ago someone on the forum asked something about managing configurations, this would be a perfect solution for me, one .fossil with the one text file, perhaps more files can be added later etc...
(21) By ramsan on 2020-04-29 08:33:37 in reply to 19 [link] [source]
If you implement option c), it should be fairly easy to script option a). The inconvenient however is that one would end up with as many commits as files need to be committed, instead of one, that would be the preferred choice.
(28) By anonymous on 2020-04-29 16:28:32 in reply to 1.1 [link] [source]
One of the most-requested feature in Fossil's history has been the ability to edit files online. On the surface, it seems like a reasonable thing to do, the main hurdle being that generation of the resulting manifest requires a checkout.
I wonder what's the problem about creating a checkout on the server-side?
When user initiates an edit session (opens a file revision for edit), the server can create a temporary checkout only with that file at the stated revision. Once the edits are confirmed, the updated file copy is committed normally. The only technical aspects are how to transfer the edited file back to server (I guess, it's via POST) and how to render this nicely on user-end. There needs to be some cookie communications to maintain state during the edit session.
Here's a sample flow:
##user logs in as USERID into REPONAME
##user open file browser for revision COMMIT-ID
##user loads a file FILEPATH into editor
##user edits the file, does SAVE for the first time
##server: receives the changed file UPD-FILEPATH
##server: generates some EDIT-SESSION-ID
##server: puts the session's ID data into the cookie
##server: creates a temp checkout for the given file
cd /tmp
mkdir fossil-$EDIT_SESSION_ID && cd fossil-$EDIT_SESSION_ID
fossil open "$FOSSILS/$REPONAME.fossil" --keep
fossil user default $USERID --user $USERID
fossil revert -r COMMIT-ID "$FILEPATH"
##server: copies the updated file into the checkout
cp "$UPD-FILEPATH" "./$FILEPATH"
##server: generates the diffs DIFF-FILEPATH to show to user for review
fossil diff "FILEPATH" > "$DIFF_FILEPATH"
##user requests to see diffs
##server renders the diffs from DIFF-FILEPATH
##user confirms the edits and commits with COMMIT-MSG
##server: commits the changes
fossil commit "$FILEPATH" -m "$COMMIT_MSG"
##server: ?? prompts if any more files to edit
## if not, then does the session clean up
fossil close --force
rm -rf "fossil-$EDIT_SESSION_ID"
##server: clears the edit session cookie
The whole bulk of effort here is on UI. Potentially, there may be a collision when two users edit the same file, or two commits co
Of course, this flow would have to be coded in, if this functionality to be supported out-of-box by fossil.exe.
(29.1) By Stephan Beal (stephan) on 2020-04-29 17:35:57 edited from 29.0 in reply to 28 [link] [source]
I wonder what's the problem about creating a checkout on the server-side?
This level of filesystem write access on a server is always problematic and a security risk. Anyone who claims otherwise has not administered enough production systems.
Just one of many potential problems is that a web server user running CGIs is not always the account holder who owns the fossil repo (that's a problem on my local dev systems but not my live hoster). If the CGI user creates a checkout (which may be arbitrarily large for any given repo), and does not clean up every single file he creates, the account holder may be left with files he can't delete later because they're owned by someone else.
Another is simply space. Doing a checkout which takes hundreds of MB may well push the account over its quota and get it locked (been there, done that).
Another is lack of portability. Some environments will make it easy and some make it difficult.
Any time a web app wants to write to the server's filesystem, it's seriously time to reevaluate the design. Of the many security holes (dozens? hundreds?) WordPress has had over the years, many, if not most, trace back to it allowing users to write stuff to server-side storage.
(30) By anonymous on 2020-04-29 18:11:53 in reply to 29.1 [link] [source]
This level of filesystem write access on a server is always problematic and a security risk.
Doesn't Fossil server need to create a .journal file when doing repo updates? That's the filesystem write access.
Another is simply space. Doing a checkout which takes hundreds of MB may well push the account over its quota and get it locked (been there, done that).
In the flow described above, the checkout is for a single file into otherwise empty directory. If that single file is that much of MBs, there's no reason it should be allowed for web-edit to begin with.
(31) By Stephan Beal (stephan) on 2020-04-29 18:37:19 in reply to 30 [link] [source]
(briefly from a tablet)
The repo db requires a journal but it's owned and managed by sqlite transparently. It's not in a location which can be served to a user, and doesn't pose any real security risk. Arbitrary user content very much does. i've been around the web hosting block a few times and have seen it happen. Black Hats invariably find a way to ruin all Nice Things.
A checkout requires a whole checkout. It cannot work with a single file. Even if it could, if we were to unpack files to the filesystem for every user, each HTTP session (not user) would require their own directory tree to work from. That opens the door for Black Hats to gain access to files they might otherwise not have (public repos can restrict access to files based on wildcards). Some people simply have too much free time and too much criminal energy.
From my point of view, and if i know Richard's point of view even half as well as i like to think i do, there is zero chance of fossil going down the route of the web interface writing to any hosted files other than repositories (which implies journal files, as they're a side effect of the writing process).
(32) By anonymous on 2020-04-29 19:34:04 in reply to 31 [link] [source]
A checkout requires a whole checkout.
'fossil open repo --keep' in empty dir does not fetch any files from repo; it does create a local checkout db-file, but not the repo content files. Then one can selectively fetch a file(s) ('revert' by names), edit and then commit the named files back in; closing the repo deletes the local checkout db-file.
Either way, server would need to maintain state of the edit session somehow. Unless it's a single-shot edit, without ability to review diffs prior to committing it. The interim edit results need to be kept somewhere AND tied to the session that made the edit.
If writing to the filesystem is "out-of-question", then repo can have a dedicated private table space just for that (non-clonable). Server would then write there.
(33) By Stephan Beal (stephan) on 2020-04-29 19:46:00 in reply to 32 [link] [source]
'fossil open repo --keep' in empty dir does not fetch any files from repo; it does create a local checkout db-file, but not the repo content files.
i didn't believe that and tested it, and sure enough...
That's not how i recall --keep working, but apparently it does. (i mis-remembered keep as checking out out all files which didn't already exist in the filesystem.)
If writing to the filesystem is "out-of-question"
It is, at least from my perspective.
then repo can have a dedicated private table space just for that (non-clonable). Server would then write there.
The problem is that the underlying code for creating manifests is intimately tied to direct filesystem access (because that's where checkouts have lived since the time of the cavemen and there was never a need for them to be anywhere else). It "could" be rewritten to optionally work solely in-db, but it would be an invasive change which nobody, so far, has been willing to make. (It's not something i'm signing up for!)
(34) By Stephan Beal (stephan) on 2020-04-30 11:47:29 in reply to 1.1 [link] [source]
Milestone: when mini-committing from a baseline manifest, it now generates a delta...
$ f test-ci-mini webci/ZFile --as ZFile --comment 'test N' -d -R webci.fsl --wet-run
Manifest 6c9d2d38c8f5e3b4ce404d2e984b5e548bfb4b0e31f9f61a6f137289d576bf27:
B 54c51ecb89595eaf4ab1f1ce94eb3d7854e3ec05e83017b9a1f7b8c8f6f85183
C test\sN
D 2020-04-30T11:15:02.747
F ZFile 8f191aaf6828f3875089d4768d61223ac4054ad820459d0d11f552d0672c1f71
P 54c51ecb89595eaf4ab1f1ce94eb3d7854e3ec05e83017b9a1f7b8c8f6f85183
U stephan
Z 0b68b37c7eba65d09369a231dfa4c63f
This particular case is the easiest one, as it always has exactly 1 F-card. Still TODO is to generate a delta when the parent is itself a delta and to provide a flag to enable/disable generation of deltas. (IMO we should prefer them for their size benefits, but there may be an argument for avoiding them.)
Sidebar: the internals are set up so that we could expose this via the web without exposing it via the CLI, if desired, but testing via the CLI is infinitely simpler.
(35) By Richard Hipp (drh) on 2020-04-30 15:05:13 in reply to 34 [link] [source]
See the "Verifying Code Authenticity" section of the SQLite respository. It is important to me to keep the SQLite repository free of delta manifests, as a delta manifest would complicate the verification algorithm.
(36.1) By Stephan Beal (stephan) on 2020-04-30 16:24:58 edited from 36.0 in reply to 35 [link] [source]
It is important to me to keep the SQLite repository free of delta manifests,
The current mini-checkin now only generates a delta if it's asked to, using the same --delta flag as commit. It also now honors the forbid-delta-manifests setting, though it then silently falls back to baseline rather than aborting like commit does.
Edit: speaking of: it can now create a delta from another delta, deriving from the same baseline as the immediate parent delta but inheriting the F-cards from the parent delta.
(37.1) By Stephan Beal (stephan) on 2020-05-01 07:41:46 edited from 37.0 in reply to 1.1 [link] [source]
Current status and next steps (for which this post is an RFC)...
- The mini-checkin infrastructure is essentially complete and working well from the CLI.
- The next step is to add the web page, which was just started but nowhere near working yet.
Currently the page requires checkin access in order to use it, but...
- We might want to consider a new permission to enable web-based edits, off by default for everyone.
- We "probably" want to restrict edits to certain file types. Maybe a new non-versionable setting which defines a list of mimetypes or filename globs for the files which can be edited. (Non-versionable so that only a user able to set config options on the "central" repo can modify it. Not that that would stop a user from using it locally if they wanted.) That would allow an admin to keep people from editing code online, while allowing them to edit embedded docs. Matching files would get a new "edit" link on the appropriate pages.
Ideas/critiques on the above 2 points would be appreciated.
It occurs to me just now that editing of some files won't be feasible. We cannot HTML-ify the content for editing purposes, as that would modify it, potentially breaking it. If the content contains certain mismatched HTML tags then the editor will break... unless we fetch the content via AJAX and feed it into the editor that way. That sounds more like a "version 2, if ever" feature, though. (That's essentially the same problem we recently had with the forum, where a post was missing a closing CODE tag.)
Edit: baby steps
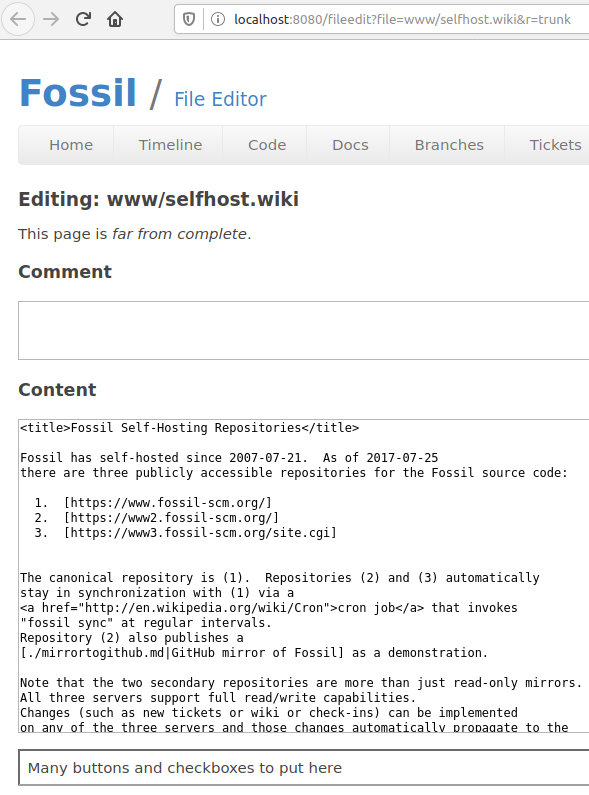{kind=link}
(38.2) By Warren Young (wyoung) on 2020-05-01 08:55:16 edited from 38.1 in reply to 37.1 [link] [source]
new permission to enable web-based edits
The next point aside, this seems an obvious extension of Write (i) cap to me.
Keep in mind that cloning and syncing most commonly happens over HTTP[S], so if a given repo manager cannot trust commits via the web, they should not trust the repo at all.
allow an admin to keep people from editing code online, while allowing them to edit embedded docs
That's unprecedented in Fossil's history. Up til now, if you can commit, you can commit, no restrictions.
If you need such a restriction, you can already get that behavior today by splitting the repository into code & docs and setting up a one-way login group arrangement between the two. Code repo editors can modify the doc repo, but not vice versa.
The fact that this scheme is orthogonal to your new feature further suggests that we've probably got a case of scope creep here.
restrict edits to certain file types
This is good, though only because not all files can be edited in an HTML <textarea>, not for your wish to create separate tiers to "i" cap.
I'd prefer that you make it a whitelist:
$ fossil set editable-glob '*.txt, *.md'
...though it could also be expressed as a blacklist:
$ fossil set uneditable-glob '*.docx, *.jpg, *.png'
I prefer the whitelist option because it's simply easier to list the subset of editables than try to collect the possible list of non-editables.
One nuance worth thinking about: if you go with the whitelist and give up on the idea of a separate web-edit cap, an "edit" click on a "non-editable" file could download it much as happens with the current MIME type handling, then offer a "Replace" feature that lets me send a new version of the file, allowing me to edit, for instance, PNG files via re-upload.
(40) By Stephan Beal (stephan) on 2020-05-01 11:24:04 in reply to 38.2 [link] [source]
this seems an obvious extension of Write (i) cap to me.
That's the current choice for me, too. My suspicion is that some people aren't going to be comfortable with allowing web edits, but that's just a suspicion.
The fact that this scheme is orthogonal to your new feature further suggests that we've probably got a case of scope creep here.
Yeah, but this one's been along time coming. When people see "web interface," some of them immediately assume that it "must be easy" to edit files over the web, especially since it's possible for a wiki. We've just always lacked the infrastructure to do it.
I'd prefer that you make it a whitelist:
That's also my current preference.
One nuance worth thinking about: if you go with the whitelist and give up on the idea of a separate web-edit cap, an "edit" click on a "non-editable" file could download it
i hadn't thought of that. Or maybe open the editor with a link which says, "can't edit, here's a download link." The current behaviour, lacking the whilelist, is that if looks_like_binary() returns true, it just fails loudly explaining that it can't edit binaries.
An upload wouldn't be a bad idea for those, either - i'll add that to the potential TODOs. Somewhere in the wiki or ticket bits we've got the infrastructure for that already.
(43) By Warren Young (wyoung) on 2020-05-01 11:55:24 in reply to 40 [link] [source]
some people aren't going to be comfortable with allowing web edits
Maybe what we want then is an Admin option to disable the feature entirely, for the benefit of those who simply don't trust web browsers to treat data reliably.
Recall that one of the arguments against this very forum was the worry that the browser would somehow eat posts. Never mind that browsers go to heroic efforts to avoid doing that, the worry still exists.
...a case of scope creep...
When people see "web interface," some of them immediately assume that it "must be easy" to edit files over the web...
You've misunderstood me. I support the existence of this feature. In fact, I've got two specific users of mine in mind who I believe will love it. All I'm against is the idea that this feature should split Write cap.
It's simply irrational to treat web edits as distinct from offline edits that then sync back over the web. They're functionally the same thing. If you don't trust someone to commit a file and then sync it, you shouldn't trust them with web editing ability, either.
if looks_like_binary() returns true, it just fails loudly explaining that it can't edit binaries.
That may be insufficient. There are files which are technically editable which shouldn't be edited in a <textarea>, so a repo maintainer may rationally wish to leave them off the whitelist.
A good example is most XML. There is usually an app made for modifying such files which should almost always be used instead. (e.g. Inkscape for SVGs.) Even if you do edit some XML files with a text editor, few file formats benefit from use of an intelligent editor as much as XML.
(44) By Florian Balmer (florian.balmer) on 2020-05-01 12:03:27 in reply to 43 [link] [source]
It's simply irrational to treat web edits as distinct from offline edits that then sync back over the web. They're functionally the same thing. If you don't trust someone to commit a file and then sync it, you shouldn't trust them with web editing ability, either.
...
There are files which are technically editable which shouldn't be edited in a
<textarea>, so a repo maintainer may rationally wish to leave them off the whitelist.
These two paragraphs seem to contradict each other. What would stop the user from doing a "non-intelligent" edit to an XML file on his local clone and then sync back?
(47) By Stephan Beal (stephan) on 2020-05-01 12:24:35 in reply to 44 [link] [source]
There are files which are technically editable which shouldn't be edited in a
<textarea>These two paragraphs seem to contradict each other.
An example of the latter is a Makefile. It's tedious to get hard tabs into a textarea (they can be pasted in, but the tab key switches to the next form element), so Makefiles "probably shouldn't" be edited that way. It's too easy to screw them up.
What would stop the user from doing a "non-intelligent" edit to an XML file on his local clone and then sync back?
Absolutely nothing. My one real concern about a web-editing interface is that people will use it even when they "really, really shouldn't," just because it's convenient to do so, and will Break Stuff. Obviously, if they break their stuff it's their fault, not the feature's, but that doesn't seem like a viable standard response when people come crying to the forum about how the web editor tempted them to break their makefiles or uncompressed ODT/DOCX files.
With great power comes great responsibility.
(48) By Florian Balmer (florian.balmer) on 2020-05-01 12:46:55 in reply to 47 [link] [source]
It's tedious to get hard tabs into a textarea (they can be pasted in, but the tab key switches to the next form element), so Makefiles "probably shouldn't" be edited that way. It's too easy to screw them up.
I'm convinced, tabs are the show-stopper, they're hard to get right. Then maybe show a warning near the textarea that tabs (and also mixed line endings †) may be screwed up, in case admins forget to blacklist every single file type that may use tabs in their project.
† Mixed line endings in text files can appear in patch files generated from fossil diff, for example, if at least one of the involved files has CR+LF line endings.
(65) By Joel Dueck (joeld) on 2020-05-01 16:25:00 in reply to 48 [link] [source]
It's trivial to write a bit of javascript that allows entry of tabs in a textarea.
I could supply a minimal working example, if I can do so without having signed a CLA. But if you Google it you'll get the idea.
Also note the tabs supplied by Fossil inside the textarea should be escaped as 	 in order to display/edit properly, similar to how angle brackets and ampersands are escaped.
(69) By Florian Balmer (florian.balmer) on 2020-05-01 17:20:40 in reply to 65 [link] [source]
I see, some early wiki engines had this, but I haven't encountered this lately, maybe it was too confusing? Personally, I try to avoid tabs, and I'm not sure if it's easy to work in a tab-enabled textarea lacking visual feedback about the type of whitespace, as can be switched on in text editors.
(49) By Warren Young (wyoung) on 2020-05-01 12:48:59 in reply to 44 [link] [source]
Let me see if I understand your position through restatement: Because someone could clone a repo and use something dreadful like Notepad to edit it, then check that change in, causing untold havoc, we should also allow unrestricted edit access to files via this new feature, so long as looks_like_binary returns false.
Have I got your position right?
If so, then my answer is that in the traditional use case (clone, edit, commit, and sync) Fossil doesn't tell you how the "edit" step works. You are presumed to be an intelligent human being with the ability to choose tools you find useful. Tools which frequently wreck files must be deemed not-useful by any rational evaluator.
Contrast this feature's use case, where we're more or less telling the user what editor to use, so we can reasonably predict what files should be edited in that editor and which shouldn't be, up front.
(I know of no useful distinction between the <textarea> implementations among browsers from the standpoint of this new feature.)
If this feature also included a powerful HTML5 programmer's editor (e.g. Monaco), then I'd accept your position: any file which can be opened should be editable via this interface.
If you were to locally integrate such an editor into your repository, then it would be rational to set the glob whitelist to '*'.
(50) By Florian Balmer (florian.balmer) on 2020-05-01 12:52:12 in reply to 49 [link] [source]
I'm convinced there's cases where this won't work, see reply 62.
(56) By Stephan Beal (stephan) on 2020-05-01 14:57:45 in reply to 49 [link] [source]
we should also allow unrestricted edit access to files via this new feature, so long as looks_like_binary returns false.
Have I got your position right?
Not my position, per se, but the current very alpha-alpha implementation, yes.
My position is more or less:
Looks like binary? Disallow it, period, or eventually offer an upload option.
Else it's UTF8 text. By default, the web interface will currently convert all newlines in the inbound content to the same type found in the original version of the file (whichever style is discovered first: as Florian points out, it's potentially possible to have mixed EOLs, but That Way Lies Madness). There is internally a flag to toggle this conversion, but the web UI doesn't yet have those checkboxes. The other option is to accept whatever the client sends, which always means CRLF because that's what HTML specifies for form-posted textareas. (That said:
cgi_parameter_trimmed()internally converts input to Unix EOLs, but i've avoided using it for that reason, to keep Windows users happy.)
Contrast this feature's use case, where we're more or less telling the user what editor to use, so we can reasonably predict what files should be edited in that editor and which shouldn't be, up front.
"We" (fossil) only know whether it's text and what EOL type it has (ignoring the mix-EOL case). We don't know, e.g., whether or not a user really wants to try to edit a Makefile in a textrea (That Way Lies Madness). That's what makes the whitelist so compelling: "we" (repo admins) can then specify which files can reasonably be edited and which cannot. The whitelist is not yet implemented, but it will be as soon as the editor is ready to integrate into the ecosystem.
We're not entirely dictating which editor to use: for non-trivial edits it seems likely that a user would copy/paste the content into their preferred editor, then paste it back for submission. (i do that quite often for forum posts if they contain non-trivial markdown, taking advantage of emacs's markdown-mode.)
(I know of no useful distinction between the
<textarea>implementations among browsers from the standpoint of this new feature.)
Nor do i.
(Pro tip: when quoting peoples posts which contain <textarea>, always re-escape that tag or else the forum editor will barf on the preview.)
If this feature also included a powerful HTML5 programmer's editor ... If you were to locally integrate such an editor into your repository, then it would be rational to set the glob whitelist to '*'.
Then and only then, yes. Such an option would also allow that editor to convert the EOLs on the client-side before submitting, then stick the converted text into a hidden form element instead of the textarea, meaning it wouldn't be subject to the textarea EOL normalization rules. We could do that, i guess, with a small bit of JS. The server can embed a flag in the form telling it what EOL style was detected for the original. Hmm. Seems safer to just do that re-conversion (if needed) back on the server, though (and the code is already in place).
My own vision of a typical whitelist is extremely conservative: *.txt,*.md,*.css, or similar. However, as Blade so beautifully put it:
"There's always some (expletive) trying to ice skate uphill." -- Blade
and i fully expect someone to try to use this, to their own grief and dismay, with Makefiles, python code, and all manner of other plain text files "because they can" and not "because it makes any sense." As the Germans say: Schuld eigene (it's their own fault). Adding a big, fat disclaimer to the top of the editor page likely wouldn't deter such people, but i'll seriously consider adding one, anyway.
In any case, this feature is in no way intended to be a replacement for having an editable copy in a checkout. It's "intended" for quick/small edits to embedded docs and the like, not source code of any sort. That said: see the above quote by Blade.
(60) By Florian Balmer (florian.balmer) on 2020-05-01 15:28:34 in reply to 56 [link] [source]
Indeed, copy-paste to text editor and back to textarea might even work with tabs.
Also, while on review and small doc update from a tablet, it may be convenient to fix typos in source code comments discovered during the process, instead of filing a ticket, or whatever.
With these two points, I don't see "web edits" as an absolute no-go for source code files.
(53) By Andy Bradford (andybradford) on 2020-05-01 14:41:58 in reply to 38.2 [link] [source]
> > allow an admin to keep people from editing code online, while > > allowing them to edit embedded docs > > That's unprecedented in Fossil's history. I agree that the ability to commit code via the web should be restricted and only enabled intentionally by an administrator under conditions that he sees fit for his project. Andy
(54) By Andy Bradford (andybradford) on 2020-05-01 14:44:54 in reply to 53 [link] [source]
However, it's possible I've misunderstood your argument. :-) Maybe you're simply suggesting that the ability to enable/disable the "commit from web" feature is independent of capabilities? Thanks, Andy
(57) By Stephan Beal (stephan) on 2020-05-01 15:00:31 in reply to 54 [link] [source]
Maybe you're simply suggesting that the ability to enable/disable the "commit from web" feature is independent of capabilities?
i wouldn't mind either approach, actually. With a whitelist, we could reasonably treat an empty whitelist as "it's disabled, so don't provide links to the editor."
(59) By Warren Young (wyoung) on 2020-05-01 15:26:46 in reply to 54 [link] [source]
it's possible I've misunderstood your argument. :-)
My argument is that this:
$ fossil clone https://example.com/repo x.fossil
...open, cd, etc....
$ vi foo.txt
$ fossil ci -m 'edited file foo.txt'
is functionally the same as "commit from web." Note the https URL. :)
Therefore, if a repo admin gives me commit access on that repo, it should not matter whether I commit via the above method or via an HTTP POST to Stephan's new feature endpoint.
I think people are trying to make an analogy here with the WrForum, WrWiki, and WrTkt capabilities, and technically it looks like they're right:
f init x.fossil
f user new fred a a -R x.fossil
f user cap fred k -R x.fossil # give user fred only WrWiki cap
f serve x.fossil &
f clone http://fred@localhost:8080 y.fossil
mkdir y
cd y
f open ../y.fossil
f user default fred
echo 'Hi!' > x.wiki
f wiki create Hi x.wiki
f push
Push to http://fred@localhost:8080
Round-trips: 1 Artifacts sent: 1 received: 0
Error: not authorized to write
IMHO, this should also be allowed, because user fred has k cap. He should not need i cap to push this artifact.
If y'all disagree and say that fossil push via HTTP is fundamentally different than HTTP POST via browser, then I'll shut up and y'all can add the new cap. But personally, I'd rather the existing interfaces be fixed to allow the push without 'i' cap if all of the artifacts being pushed are of types allowed by the user's other capabilities, if possible.
(61) By Stephan Beal (stephan) on 2020-05-01 15:39:58 in reply to 59 [link] [source]
If y'all disagree and say that fossil push via HTTP is fundamentally different than HTTP POST via browser,
i don't disagree, and only suggest a new perm as an option for the sake of those who are unsettled by the potential for "runaway users" who want to use this New Superpower to edit the C code online or some such (That Way Lies Madness). (The temptation will be there, certainly, but... madness.) A whitelist glob would suffice just as well, except that it would apply to all users (which is arguably a better approach).
A whitelist is a given, i think - there's no(?) sensible argument against it and there are good reasons for it. Whether or not we really need a new permission, i'm actually ambivalent.
(63) By Joel Dueck (joeld) on 2020-05-01 16:09:25 in reply to 61 [link] [source]
I would say that fossil push via HTTP is fundamentally different than HTTP POST via browser, in at least one respect: when working from inside your browser, there is no possible way to test your changes before you commit them.
This is not so much of a concern with embedded docs and it would be really nice to have the web interface for those. But as a repo admin, I would like to forbid web editing of anything else, since it would allow people to check in code that they would not/could not have tested. Otherwise they might be tempted to use it for quick code edits.
(64) By Stephan Beal (stephan) on 2020-05-01 16:14:21 in reply to 63 [link] [source]
Otherwise they might be tempted to use it for quick code edits.
Temptation is the real bugbear here.
Perhaps if it detects checkins to any source code, it should force the user through three levels of capchas and then, at the end, fail mysteriously with the message, "please try again later." :)
(67) By Larry Brasfield (LarryBrasfield) on 2020-05-01 16:40:15 in reply to 64 [link] [source]
I'm interjecting here because I see an undercurrent worth diverting.
Yes, online, quick edits without a check-out could be misused. In fact, an irresponsible developer might be tempted to do a "quick fix" of a problem without properly vetting it even if the check-out file set is conveniently available with which to do a build and whatever pre-commit testing is mandated.
However, as tool-makers (or tool-enhancers), those are not problems for fossil's developers to solve. They are problems which should motivate creation of features allowing either a repo administrator or individual repo users who wish to avoid inadvertently "breaking the build" or "failing the usual test suite" to limit check-ins according to criteria that suit them.
When I have worked with many other developers, check-in policies were made quite explicit. Penalties for violating them were not quite as explicit, but nobody was in doubt as to what would be considered irresponsible. In those circumstances, I could only imagine the predicament and potential embarrassment that could flow from abusing the check-in privilege I had. I never went there, and with very rare exceptions, nobody else did either, and the exceptions were not repeated.
IMO, the fossil developer concerns should be with enabling repo managers to mitigate their own concerns. And when assessing how to do that, we should not forget that with a normally setup fossil repo, (and with the possible exception of 'purge'), any mischance can be undone with moderate effort.
As for disallowing "code" edits from afar (without a check-out), I would point out that some documentation is extracted from code. It would be a perfectly reasonable check-in policy that doc improvements do not require the rebuild and retest that functional code changes do. And those should be allowed (per local policies, set by the repo manager(s)) even if the "doc" is embedded in "code".
(70) By Joel Dueck (joeld) on 2020-05-01 18:08:51 in reply to 67 [link] [source]
the fossil developer concerns should be with enabling repo managers to mitigate their own concerns.
Yep. This exact sentiment is why we are discussing/proposing a whitelist. Repo managers should be able to set their own policy to be as permissive or as restrictive as they like.
(66) By Warren Young (wyoung) on 2020-05-01 16:26:57 in reply to 63 [link] [source]
there is no possible way to test your changes before you commit them.
Okay, that argument I buy. :)
(119) By ravbc on 2020-05-04 15:31:21 in reply to 61 [link] [source]
There is at least one more difference between fossil push via HTTP and HTTP POST via browser. With fossil push user can edit any file in the repo.
With this new feature, when an admin sets a whitelist (and the "edit via upload" will be unavailable or controlled separately), then the user could web-edit only whitelisted files.
(39.1) By Florian Balmer (florian.balmer) on 2020-05-01 10:54:07 edited from 39.0 in reply to 37.1 [link] [source]
We "probably" want to restrict edits to certain file types. ... We cannot HTML-ify the content for editing purposes, as that would modify it, potentially breaking it. ...
That's no problem. Just escape:
& → &
< → <
> → >
Like this, text can be output as the default contents of a textarea. Also note that browsers will send back unescaped text.
I'm sure fossil_printf() already has a format specifier for this!
Moreover, consider the following C source code file:
char *zBreakMe = "</textarea>";
This example shows that "lists of file types" won't be useful to decide whether or not a file is suitable for online editing.
A more robust approach may be to check if a file has binary contents, the same way Fossil already does when generating diffs (see src/lookslike.c). For binary files, the "edit" page could abort with a warning (or offer to upload a replacement file, at a later stage).
Is it already clear whether the CLI part will be a separate new command, or squeezed into the commit command? I hope the former ... ;-)
Edit: the only thing to worry about is that web editing will break non-UTF-8 text files.
(41.3) By Stephan Beal (stephan) on 2020-05-01 11:42:49 edited from 41.2 in reply to 39.1 [link] [source]
That's no problem. Just escape:
Until we escape some C code, all of the < get escaped, and then the user posts an edit back. That would effectively corrupt the file.
Another idea came to mind about how we could do this: pack the content base64-encoded into a hidden data url or field, unpack it on the client, and set it via JS. That bypasses all of the escaping issues. That would, however, require a small bit of JS (which now includes base64 encoding/decoding, so would require no 3rd-party code).
Edit: nevermind: JS's built-in base64 apparently only works with ASCII. Bummer.
char *zBreakMe = "</textarea>";This example shows that "lists of file types" won't be useful to decide whether or not a file is suitable for online editing.
That's exactly the kind of case i was thinking of. The list of types would certainly not protect against everything, it could be used to disable editing of "potentially problematic" files like source code or HTML.
A more robust approach may be to check if a file has binary contents, the same way Fossil already does when generating diffs (see src/lookslike.c)
That's already done, actually, but it currently simply fails if it looks like binary. i hadn't thought of an upload until you and Warren mentioned it.
Is it already clear whether the CLI part will be a separate new command, or squeezed into the commit command? I hope the former ... ;-)
It has not been decided. We don't desperately need the CLI part except to please our one or two(?) anonymous posters who has/have been asking for this.
The infrastructure was written to accept input from any source only because it's 250x faster/easier to develop/test from the CLI. We're not required to expose that ability, though, or it could (as it is now) be kept as an unsupported test command, left there primarily for development of the web-side feature. (All the CLI part does is collect args and populate a structure, which it then passed on to an infrastructure-level routine which processes it, including all validation. The web front-end will essentially do the same thing.)
Edit: the only thing to worry about is that web editing will break non-UTF-8 text files.
looks_like_binary() is just a proxy for looks_like_utf8(), and that will fail (meaning it will look like binary) for non-UTF8. There are no intentions of supporting arbitrary encodings this way - that's way, way out of scope and potentially... problematic.
(42) By Florian Balmer (florian.balmer) on 2020-05-01 11:54:55 in reply to 41.3 [link] [source]
Until we escape some C code, all of the < get escaped, and then the user posts an edit back. That would effectively corrupt the file.
Hm, this should work fine. Web browsers are aware that the default contents inside of the textarea element has to be escaped so as not to break the textarea itself, but the text effectively displayed by the textarea will be unescaped, and will also sent back unescaped.
I've been doing this all the time, in my early web hacking days, with the PHP htmlspecialchars() function:
echo '<textarea>'.htmlspecialchars($anytext).'</textarea>';
Try this example:
<html>
<body>
<textarea id="test">
&<>
</textarea>
<script>
alert(document.getElementById('test').value);
</script>
</body>
</html>
You will see &<> both inside the textarea and in the message box -- and this is also what the browser will post back.
(45) By Stephan Beal (stephan) on 2020-05-01 12:17:23 in reply to 42 [link] [source]
You will see &<> both inside the textarea and in the message box -- and this is also what the browser will post back.
i'll need to experiment with that. i don't recall ever having had problems with this in the past, but now i'm a bit nervous about it because What Gets Stored in Fossil Stays in Fossil, so extra care is needed.
(46) By Florian Balmer (florian.balmer) on 2020-05-01 12:23:14 in reply to 45 [link] [source]
The wiki and forum editors already do this, and things work fine! It's no problem to insert &<> in a wiki page or a forum post, and edit it later -- with a "server-side prepopulated" textarea on editing.
(52) By anonymous on 2020-05-01 14:39:13 in reply to 46 [link] [source]
Well sort of.
The reason the wiki works is that the consumer of the text is the wiki which knows how to reconstitute html.
What happens if in c code, I literally want '>'. I need to edit it as:
&gt;
right? which is not what it would look like in C. Also it would not produce the correct result in C as it doesn't know how to turn & into &.
(Note I had to do two edits when entering this to get multiple sets of entity relationships escaped. Otherwise it was replacing the 5 character entity that I wanted displayed with the literal & character.)
(68) By anonymous on 2020-05-01 16:41:47 in reply to 52 [link] [source]
What happens if in c code, I literally want '>'.
You type it as > in the textarea and nothing bad happens whatsoever. The browser sends it as > to the server, too. The problems with literal &entities; on this forum only happen because the server tries to interpret your submission as Markdown, which incorporates some HTML, which causes the entities to be expanded after they are rendered on a web page sent back to you.
The escaping only needs to happen on the server when rendering arbitrary text into <textarea> content. The simplest way to perform that would be to encode each character into a numeric character reference (&#xxxx;), but you can use a smarter method and only encode the characters that need encoding. When the browser sees these entities inside a <textarea> tag, it decodes them back into the original text and presents the result to you. Once you submit the form, the HTTP POST request uploads the data literally, without any additional HTML entity encoding or decoding.
(Well, strictly speaking, two more things can happen: if some of the characters entered by the user cannot be encoded into the form's accept-charset (which usually matches the encoding of the web page the form belongs to), the browser may send them as HTML entities instead. Or send some mojibake. Or do something else. But with UTF-8 as page encoding this cannot happen, because UTF-8 encodes all of Unicode. And HTTP POST may use some other kind of encoding, not related to HTML entities, depending on the Content-type of the form - application/x-www-form-urlencoded vs multipart/form-data - but that happens transparently.)
(55) By Warren Young (wyoung) on 2020-05-01 14:45:42 in reply to 45 [link] [source]
Would it be heretical to suggest use of Ajax here?
That is, rather than ship an HTML-escaped version of the file down with the "edit" page, send just the editor for the doc and have in-page JS pull the file contents via a /raw URL during page onload processing. This ensures that you get the file data byte-for-byte.
It is then up to the browser to ship back the edits without damaging the file.
Yes, yes, I know, this is going to wind the small-but-noisy anti-JS contingent up. For them, we can build in a fallback case where the this mode is only triggered when the page that calls the editor sees that JS is available. If not, then the Fossil server still has to try to HTML-escape the doc text as best as it can.
(58.1) By Stephan Beal (stephan) on 2020-05-01 15:25:46 edited from 58.0 in reply to 55 [link] [source]
Would it be heretical to suggest use of Ajax here?
It would be a perfectly reasonable thing to do, especially for loading the file's contents, as that bypasses any and all escaping issues. If we have an unclosed TEXTAREA tag which got injected via theTextarea.value = itsContents, that doesn't break anything. That was one of the proposals for forum content, but the performance hit in that context would be tremendous. For this context, with only 1 editor and preview/diff slots, the impact would be marginal.
This ensures that you get the file data byte-for-byte.
i may be misinterpreting what the HTML standard means by "the original value" - that's apparently the only one which is not normalized. My understanding of "original value" is the content embedded between the tags. Aside from the "original value," EOL normalization still applies (differently in different contexts "for historical reasons").
Because the textarea EOL normalization is so wonky, it seems safer to me to do it on the server side and simply use what the previous version used. This feature does not permit the addition of new files via the web (it can optionally do so via CLI), so we always have a basis to work from except in the unusual case of a parent with no EOLs (e.g. empty or one line), in which case we have to pick an EOL style or require that the user tell us via a SELECT box ("Same as previous version", "Unix", "Windows").
Yes, yes, I know, this is going to wind the small-but-noisy anti-JS contingent up. For them, we can build in a fallback case where the this mode is only triggered when the page that calls the editor sees that JS is available. If not, then the Fossil server still has to try to HTML-escape the doc text as best as it can.
We could possibly also reasonably say that this specific feature requires JS. Seriously, every major site uses JS and it's an inseparable part of HTML5, whereas JS was considered "kinda optional" in HTML4. People who disable JS then simply lose access to this feature - they can use a checkout instead, like the universe intended in the first place.
That said: the amount of JS needed to handle loading/submission of the data over XHR, as opposed to a FORM submit, would be quite small. We're talking a few kb, 10kb tops, not 50kb. Especially if we use the not-yet-quite-ubiquitous fetch() API instead of XHR, which is just plain wonky but works.
(72) By Stephan Beal (stephan) on 2020-05-02 11:38:02 in reply to 58.1 [link] [source]
Would it be heretical to suggest use of Ajax here?
It would be a perfectly reasonable thing to do, especially for loading the file's contents, as that bypasses any and all escaping issues.
... the amount of JS needed to handle loading/submission of the data over XHR, as opposed to a FORM submit, would be quite small.
After sleeping a night on it, i've gone with the AJAX for loading the content, using the HTML5/XHR2 interface, which is slightly less wonky than historical XHR and is supported everywhere except for Opera Mini (which is embedded in some handheld game consoles, but not much else, AFAIK). (Note that the specific API features not supported by MSIE and pre-5.0 Android are not features we need to use.)
Here's a screenshot of the current code which loads the file's content using, as Warren suggested, /raw:
https://fossil.wanderinghorse.net/screenshots/fossil-fileedit-fetch-content1.png
{kind=link}
The top panel is the generic script for loading/posting content, a pseudo-standin for the not-quite-standard window.fetch() method. The bottom panel shows it being used for loading the file editor's content and populating the editor.
This approach completely eliminates the "stray textarea tag problem" because content assigned to the textarea this way is not part of the visible DOM, thus it never gets inspected by the HTML parser. It also means that we have to do no potentially risky conversion of any text, namely HTML tags.
If there are strong objections...
... to this approach, please voice them. The alternative to this approach is to always live with the danger that certain content will, because it contains a textarea tag, simply break the page. We also might (this is not yet certain) have to encode certain elements for display in the textarea, a problem we don't have with the AJAX approach.
If you object, please keep the following in mind: loading the content via AJAX is the only way the page can safely deal with the wide range of content people have in their trees. To implement it without JS would leave it completely unable to deal with certain plain text files because they contain stuff the HTML parser will choke on. Having the editor app escape tags on users' content is a quick path to madness, as we can never know, with certainty, what needs to be unescaped when saving.
(73) By Florian Balmer (florian.balmer) on 2020-05-02 12:06:17 in reply to 72 [link] [source]
No need to unescape anything, browsers will post back verbatim text.
Anyway, AJAX should work -- but in case "preview" and "diff" reload the whole page, this will be more complicated to handle, i.e. they should also use an XHR to reload just the required parts, or the escaping problem will reappear ...
(74) By Florian Balmer (florian.balmer) on 2020-05-02 12:47:56 in reply to 73 [link] [source]
P.S. The same goes for "save" if there's an error, and the textarea has to come back with the modified text ...
(76.1) By Stephan Beal (stephan) on 2020-05-02 15:05:01 edited from 76.0 in reply to 74 [link] [source]
P.S. The same goes for "save" if there's an error, and the textarea has to come back with the modified text ...
i just now discovered that by accident :/.
Edit: the rest of this post is no longer applicable. See the follow-up responses for details.
That's a problem.
Semi-related, i've been thinking about adding a "drafts" table which stores, per user, one piece of arbitrary "draft" content. Storing the being-edited content there would allow it to be fetched via AJAX.
Aside from using a table like that one, i'm not sure how to solve this.
Suggestions?
At its most basic, the "drafts" table could look something like:
CREATE TABLE user_drafts(
user TEXT PRIMARY KEY, -- user name
content BLOB NOT NULL,
UNIQUE(user) ON CONFLICT REPLACE,
FOREIGN KEY(user) REFERENCES user(login) ON DELETE CASCADE ON UPDATE CASCADE
) WITHOUT ROWID;
-- And for time-based cleanup:
CREATE TABLE user_drafts_time(
user TEXT PRIMARY KEY, -- user name
mtime INTEGER, -- for expiry/cleanup
UNIQUE(user) ON CONFLICT REPLACE,
FOREIGN KEY(user) REFERENCES user_drafts(user) ON DELETE CASCADE ON UPDATE CASCADE
) WITHOUT ROWID;
It would be limited to users with Write access and would be accessible via /draft, where it would automatically fetch the current draft, if any, for the current user in raw format. For non-users and those without a draft it would return an error.
:-?
(78) By Stephan Beal (stephan) on 2020-05-02 14:00:16 in reply to 76.0 [link] [source]
Aside from using a table like that one, i'm not sure how to solve this.
We don't need a table for that case, we just need to simulate it...
When POSTing edits, instead of loading the content async, we instead pack the POSTed text into a JSON string (which sqlite3 can encode for us), and restore that string to the textarea upon loading.
Whew... i was not looking forward to trying to justify a schema addition.
:-D
(79.3) By Stephan Beal (stephan) on 2020-05-02 14:59:40 edited from 79.2 in reply to 78 [link] [source]
We don't need a table for that case, we just need to simulate it...
Solved!
/* Populate doc... */
fileedit_emit_script(0);
if(submitMode==0){ /* ==> initial page hit */
fp("window.fossilFetch('raw/%s',"
"{"
"onload: (r)=>document.getElementById('fileedit-content').value=r,"
"onerror:()=>document.getElementById('fileedit-content').value="
"'Error loading content'"
"});", zFileUuid);
}else if(blob_size(&cimi.fileContent)){
db_prepare(&stmt, "SELECT json_quote(%B)",&cimi.fileContent);
db_step(&stmt);
fp("document.getElementById('fileedit-content').value=%s;",
db_column_text(&stmt,0));
db_finalize(&stmt);
}
fileedit_emit_script(1);
Edit: it turns out we can eliminate the ajax altogether by doing the same thing for the db-side content, though whether this is more or less efficient depends on the size of that content. It saves us the AJAX bit, though:
/* Populate doc...
** To avoid all escaping-related issues, we have to do this one
** of two ways:
**
** 1) Fetch the content via AJAX. That only works if the content
** is already in the db, but not for edited versions.
**
** 2) Store the content as JSON and feed it into the textarea
** using JavaScript.
*/
fileedit_emit_script(0); /* opens SCRIPT tag with nonce */
{
char const * zQuoted = 0;
if(blob_size(&cimi.fileContent)>0){
db_prepare(&stmt, "SELECT json_quote(%B)",&cimi.fileContent);
db_step(&stmt);
zQuoted = db_column_text(&stmt,0);
}
fp("document.getElementById('fileedit-content').value=%s;",
zQuoted ? zQuoted : "''");
if(stmt.pStmt){
db_finalize(&stmt);
}
}
fileedit_emit_script(1); /* closes SCRIPT tag */
(85) By Florian Balmer (florian.balmer) on 2020-05-02 16:44:51 in reply to 79.3 [link] [source]
An all-AJAX approach would also work without intermediate server storage: the click-handler sends the text and metadata to an API-URL, and gets back HTML for "preview" and "diff" to be appended to the current page, and a status code for "save".
Your custom JSON-encoding solution is smart and will work nicely! But I predict you'll experience a wonderful "Aha-Effekt" once you realize that you've reinvented the wheel :-) Fossil is not the first program to enable online file editing -- this problem has been solved long before JSON and AJAX.
(90) By Stephan Beal (stephan) on 2020-05-02 17:19:42 in reply to 85 [link] [source]
An all-AJAX approach would also work without intermediate server storage: the click-handler sends the text and metadata to an API-URL, and gets back HTML for "preview" and "diff" to be appended to the current page, and a status code for "save".
Submitting those via AJAX is something i would like to eventually implement, but developing the extra /fileedit_save API didn't seem worth the effort for this weekend - i'm quickly reaching the limit on how much my hands can take in one code sprint. That is definitely a potential TODO, though.
The JSON API (which is off by default) has exactly such APIs for previewing and diffing wiki edits, and we can probably recycle some of that and use sqlite's JSON API for the result output.
Your custom JSON-encoding solution is smart and will work nicely!
Yeah, i was rather happy about that :).
But I predict you'll experience a wonderful "Aha-Effekt" once you realize that you've reinvented the wheel :-)
Kinda - we save ourselves the AJAX hit this way. i'm not at all anti-Ajax, but i like it much better that this particular content can be delivered together with the page, as that avoids any error handling related to timeouts and whatnot.
Fossil is not the first program to enable online file editing -- this problem has been solved long before JSON and AJAX.
If there's a non-JSON/non-AJAX solution which avoids all of the content-embedded-in-HTML escaping-related problems we might run into with arbitrary user-supplied content, i'd be happy to hear about it. Escaping user input directly into the raw HTML output, in such a generic context, is simply not an option - we cannot possibly know how/whether to unescape it when saving.
(97) By Warren Young (wyoung) on 2020-05-02 23:47:25 in reply to 79.3 [link] [source]
SELECT json_quote(%B)
That fails if the document text is considered numeric in JSON.
Simple test case:
sqlite> create table a(b);
sqlite> insert into a values("3.14");
sqlite> select json_quote(b) from a;
3.14
That is, you do not get "3.14" (quoted) as expected. This may then cause a problem in the subsequent value assignment.
There are doubtless other failure cases, such as "document begins with open curly brace".
I think you'll have to go full belt-and-suspenders to handle all cases:
SELECT json_object('content', CAST(%B AS TEXT))
The explicit cast may not be necessary depending on SQLite's type conversion rules.
Then on the JS side:
try {
const doc = JSON.parse('%s');
document.getElementById('fileedit-content').value = doc.content;
}
catch (e) {
console.log('Failed to parse doc JSON: ' + e.message);
}
For insertion into the C code of Fossil, you probably want to make this into a one- or two-liner and inline the doc temporary. I've just presented it that way here for ease of reading.
This method also has the virtue that it avoids any sort of "JSON injection" type of failure and gets you a better diagnostic if the server-side encoding isn't perfect.
(98.1) By Stephan Beal (stephan) on 2020-05-03 08:14:39 edited from 98.0 in reply to 97 [link] [source]
The numeric/boolea/null case isn't a problem, as that will simply convert to a string on assignment. Indeed, a doc which starts with a squiggly or square brace might be an issue - i will take a look at this today. Thanks for pointing it out!
The JSON.parse isn't actually necessary, by the way, because quote converts a basic data type (non-object/array) to its JSON representation, which is always usable as-is in JS. In Douglas Crockford's JSON.parse(), which is the basis of the standard one, 99% of the code is verifying that it's syntactically valid and then, at the end, it passes the whole JSON to JS's eval to do the actual conversion. The syntax check is basically just to ensure that no functions can be called by that eval.
(99) By Stephan Beal (stephan) on 2020-05-03 08:39:36 in reply to 98.1 [link] [source]
The numeric/boolea/null case isn't a problem, as that will simply convert to a string on assignment. Indeed, a doc which starts with a squiggly or square brace might be an issue - i will take a look at this today.
My statement about how quote works as wrong:
quote converts a basic data type (non-object/array) to its JSON representation
This is actually exactly the behaviour we want:
sqlite> select json_quote('[1,2,3]');
"[1,2,3]"
sqlite> select json_quote('{"a":"hi","b":2.0}');
"{\"a\":\"hi\",\"b\":2.0}"
When those are assigned to the textarea, they'll be unescaped by JS and represented exactly as they appear in the documentmisref... with the exception(?) of their original indentation, which could be a genuine issue, albeit a cosmetic one (it will affect editing of JSON files, but it won't break them semantically). That said, i have not yet tested indented/formatted JSON, but will today.
misref = to see this in action, simply paste those strings into a JS dev console, wrap them in a call to console.debug(), and tap enter:
console.debug("{\"a\":\"hi\",\"b\":2.0}")
undefined
{"a":"hi","b":2.0}
That's a string, not an object: the console highlights objects differently, which we can see by doing:
console.debug("{\"a\":\"hi\",\"b\":2.0}",{a:1})
{"a":"hi","b":2.0} Object { a: 1 }
(100.2) By Stephan Beal (stephan) on 2020-05-03 08:51:33 edited from 100.1 in reply to 99 [link] [source]
... with the exception(?) of their original indentation, which could be a genuine issue, albeit a cosmetic one (it will affect editing of JSON files, but it won't break them semantically). That said, i have not yet tested indented/formatted JSON, but will today.
Well, that was easy. They're treated as a plain string through the whole process, so them being an object/array is not a problem and their indentation is kept 100% intact. No code changes needed.
:-D
(Whew.)
Edit: Forum-level Milestone! According to gmail, this was the 100th post in this thread and the thread isn't even about git or forking! (The post counter currently says it has 123 entries.)
(81) By anonymous on 2020-05-02 15:19:52 in reply to 78 [link] [source]
What if the Save Draft action would commit into a private branch?
This private branch insulates the edits from the rest of users. Allows as many drafts as needed. On publishing the final version, the tip of the branch should merge into its parent branch. If merge is ok, the private branch could be deleted.
(82) By Stephan Beal (stephan) on 2020-05-02 15:38:00 in reply to 81 [link] [source]
What if the Save Draft action would commit into a private branch?
That's a complication i'm going to avoid for the time being, as i've found a fairly nice way around the need for the drafts table, but should drafts ever become unavoidable, or potentially terribly useful, that might be an interesting way to go about it.
Drafts are a feature i've often wanted in the wiki and forum, but there are multiple hassles involved with implementing them which always seemed to make it not worth the trouble. In any case, that's a separate feature which would need its own generic infrastructure (to make it useful in multiple contexts), to potentially be implemented on another rainy day.
(75) By anonymous on 2020-05-02 13:45:40 in reply to 72 [link] [source]
The alternative to this approach is to always live with the danger that certain content will, because it contains a textarea tag, simply break the page. We also might (this is not yet certain) have to encode certain elements for display in the textarea, a problem we don't have with the AJAX approach.
I think that you are mistaken here. Only reserved characters are interpreted in HTML. Replacing them left-to-right with corresponding &entities; is enough to create HTML that the browser will interpret as original content. If you want to be really paranoid (in the good sense of the word), replace every character with a numeric character reference: no chance of the original text being interpreted as HTML because there is no original text any more! This would ~quadruple the size of the content, though.
Having the editor app escape tags on users' content is a quick path to madness, as we can never know, with certainty, what needs to be unescaped when saving.
The editor does not need to escape anything because the form contents are sent back to the server literally. (The only theoretically possible caveat is encoding mismatch between server and client -- but we only allow users to edit UTF-8 documents and have UTF-8 encoded pages, which gives the clients the whole Unicode to work with and prevents encoding issues.)
The forum is different because the text we submit to the server gets additionally interpreted by the server as Markdown, which contains a subset of HTML -- there is no danger of that happening to documents being edited as plain text. The </textarea> problem is a bug in Fossil's Markdown implementation that's hard to fix because HTML tags are allowed in Markdown.
(77) By Stephan Beal (stephan) on 2020-05-02 13:58:22 in reply to 75 [link] [source]
I think that you are mistaken here. Only reserved characters are interpreted in HTML. Replacing them left-to-right with corresponding &entities; is enough to create HTML that the browser will interpret as original content.
The problem is not the conversion for display, but saving edits. We simply cannot sensibly perform any conversions, other than EOL style, on the POSTed data, else we risk writing something other than the user intended.
The editor does not need to escape anything ...
It does if we embed the file content directly in the textarea. In that case, a dangling textarea tag or a closing textarea tag in the file content will completely break the page.
If we use ajax to populate it, no escaping is needed.
... because the form contents are sent back to the server literally.
Consider a file which already has some problematic characters encoded in & form and some not. We would have to convert the remaining ones, but it would be a one-way conversion: we could not possibly know which ones we converted and which ones not, and therefore could not possibly restore those parts of the file to their original form.
Again, though: this only applies if we embed the file content literally into the textarea tag.
The ajax approach is definitely the right way to do this, as it avoids all of those problems. However, it has the problem that POSTing data needs to stash it somewhere temporarily so that when the page is re-rendered, it can fetch that copy asynchronously. That is important for preview-, diff- and dry-run modes.
Doh... we don't need async for that case... will update my previous post for why...
(83) By graham on 2020-05-02 16:21:48 in reply to 77 [link] [source]
I've no problem with AJAX being used to load the area, but:
It does if we embed the file content directly in the textarea. In that case, a dangling textarea tag or a closing textarea tag in the file content will completely break the page
I don't believe so, because the opening < and closing > of <textarea> would be escaped when it is embedded (as would any & and ") and be sent as <textarea>. The browser will decode this when rendering to display <textarea> (within the textarea). For a noddy example:
<html>
<body>
<h2>Editor</h2>
<form action="/" method="POST">
<textarea name="edited" rows="10" cols="40">dsadasddsd
asdasasdadsad
asdasdadasdd
<textarea>
asdasdasdasda
aasdasdasdada
</textarea>
<input type="Submit" value="Submit" />
</body>
</html>
will display correctly.
When POSTed, the content (e.g. <textarea>) will be x-www-form-urlencoded to protect it in transit back to the server. In the above, if no changes are made, the payload is:
edited=dsadasddsd%0D%0Aasdasasdadsad%0D%0Aasdasdadasdd%0D%0A%3Ctextarea%3E%0D%0Aasdasdasdasda%0D%0Aaasdasdasdada%0D%0A
which can safely be decoded back to the the results of editing. (An embedded closing </textarea> tag also survives).
(84) By Stephan Beal (stephan) on 2020-05-02 16:37:52 in reply to 83 [link] [source]
I don't believe so,
Type an unescaped <TEXTAREA> tag into the forum editor and tap the preview button. (Just copy and paste this line, as that will leave out the markdown backticks.)
If you're lucky, the back button will recover you from it without losing what you've typed so far.
The forum editor cannot escape HTML because both fossil wiki and markdown formats permit HTML (or some subset of it).
because the opening < and closing > of
<textarea>would be escaped when it is embedded (as would any & and ") and be sent as <textarea>.
That's the problem: for an editor of generic user-provided files, as opposed to wiki pages or forum posts, we cannot escape the content because we cannot possibly know what parts to unescape when saving it.
In any case, both the AJAX and inject-via-JSON options make it a moot point, in that they both inherently bypass all such issues. The one tiny nitpick is that both require JS (but that's a small price to pay for keeping the file contents 100% intact).
(87) By anonymous on 2020-05-02 16:57:29 in reply to 84 [link] [source]
Here you go: Type an unescaped <TEXTAREA> tag into the forum editor and tap the preview button. (Just copy and paste this line, as that will leave out the markdown backticks.) It's the HTML processing of user-submitted text that breaks stuff that happens on the server that's the cause of breakage, but it shouldn't happen when editing arbitrary text via web UI. A literal <textarea> can be represented inside <textarea> without any problems. And so can <textarea>, which can be distinguished from the first one. And even &lt;textarea&gt; - no problems whatsoever.
(89) By Stephan Beal (stephan) on 2020-05-02 17:07:51 in reply to 87 [link] [source]
Here you go:
And now try again with markdown format, not plain text. In plain text mode, the forum escapes that <TEXTAREA> tag. i promise, it does not work.
Escaping is now 100% a non-issue, in any case.
(86) By anonymous on 2020-05-02 16:52:15 in reply to 77 [link] [source]
The problem is not the conversion for display, but saving edits.
But no conversion is needed for saving edits at all. The only place where the conversion is needed is display, i.e. sending the HTML page with the textarea tags to the client. When the client sends the content of the form back to the server, it sends it literally.
It does if we embed the file content directly in the textarea. In that case, a dangling textarea tag or a closing textarea tag in the file content will completely break the page.
When embedding file content directly in the textarea, we have to HTML-escape it. That is not a problem because the browser interprets the escaped text back into original text before displaying the result inside the textarea element. The process does not destroy any information or introduce any ambiguities. A few examples:
| Literal text we want to present to the user | HTML representation |
& |
& |
& |
&amp; |
" |
" |
"" |
"&quot; |
Consider a file which already has some problematic characters encoded in & form and some not. We would have to convert the remaining ones, but it would be a one-way conversion: we could not possibly know which ones we converted and which ones not, and therefore could not possibly restore those parts of the file to their original form.
Suppose there is a file containing the text </textarea> & & and we want to present it in a textarea element. We process it through an HTML-escaping function (I believe that Fossil already has one), which returns: </textarea> &amp; &. Note the different character sequences used to encode an HTML entity & and a literal &. When the browser receives the HTML-escaped string, it decodes it back to literal </textarea> & & and and places the resulting text into the textarea element. When the user presses Submit, the browser encodes that literal text (not its HTML representation) into application/x-www-form-urlencoded or multipart/form-data and sends it to the server, but, again, the process is lossless and reversible.
Could you provide an example of text you think we wouldn't be able to represent this way?
(91) By Stephan Beal (stephan) on 2020-05-02 17:36:58 in reply to 86 [link] [source]
Suppose there is a file containing the text </textarea> & & and we want to present it in a textarea element. We process it through an HTML-escaping function (I believe that Fossil already has one), which returns: </textarea> & &. ... When the user presses Submit, the browser encodes that literal text (not its HTML representation) into application/x-www-form-urlencoded or multipart/form-data and sends it to the server, but, again, the process is lossless and reversible.
The process is only reversible if users are not allowed to edit the content. As soon as they touch one byte, we cannot possibly know which parts are legal to reverse the process on. They may well have entered data in entity-escaped form with the intent that it be saved that way.
Also, try editing an XML file using that approach. That Way Lies Madness.
When it comes to user content, we're taking Exactly Zero chances that any sort of conversion will inadvertently change a single byte (except for EOLs, where we require some leeway but offer multiple options). There are C, TCL, Perl, PHP, HTML with embedded JS (also with embedded HTML), etc. files with embedded HTML/XML tags, both escaped and unescaped, in them out there and the idea of escaping those for display, then back again on POST, literally makes me ill to my stomach.
In any case, escaping is a 100% non-issue now. It's a dead topic and a dead horse, so there's no sense in beating it further.
(92) By anonymous on 2020-05-02 18:44:45 in reply to 91 [link] [source]
As soon as they touch one byte, we cannot possibly know which parts are legal to reverse the process on.
Sorry, this part is wrong. By the time the user can touch the text, the browser has already decoded the whole textarea content from entities to literal text, and no partial re-encoding back into HTML can occur. When the server sends you <textarea><tag></textarea>, you only see literal <tag> inside the textarea element, and <tag> - not <tag>! - gets sent back to the server when you press Submit. If you add or remove an HTML-special character, it stays literal, with no HTML-escaping applied on top, neither in the form, nor when the form is sent.
Take a look yourself:
create an HTML file
<html><body> <form action="http://localhost:4242/" method="POST" enctype="multipart/form-data"> <textarea name="text"> <textarea> & &amp; </textarea> <input type="submit"> </form> </body></html>run
nc -l -p 4242or use any other way to listen on TCP port 4242 and read incoming trafficmake any edits you want in the textarea element and click Submit
watch the browser's request to you (the browser will eventually say that it timed out, but it's the request, not the response that's important here)
You should be able to see no extra HTML-encoding retained from the source code or applied on top of the data you entered. Note that if you remove enctype="multipart/form-data", the data is sent percent-encoded, which is a really hard to read but reversible transformation that the browser applies for most form submissions in Fossil.
Unless the users decide to peek at the source code of the page, they are not exposed to the escaped text; they are only shown, and can edit its interpretation, and whatever the user sees inside the textarea element gets sent to the server literally. There is absolutely no chance of confusing something that browser sends to the server via POST with its representation in HTML entities.
They may well have entered data in entity-escaped form with the intent that it be saved that way.
And they will be saved that way, because browsers are expected to send the form contents literally... subject to application/x-www-form-urlencoded or multipart/form-data, but that's unavoidable whether you use XHR or not. You won't get HTML entities from a browser unless they were literally typed into a textarea element.
escaping those <...> back again on POST
The form encoding that happens on POST is unavoidable, but has nothing to do with escaping HTML entities and is 100% reversible (e.g. you can send binary files via POST with application/x-www-form-urlencoded despite every byte being transformed into a hexadecimal number %xx while in transit, and then transformed back by the server while it reads the request). HTML entities are never escaped on HTTP POST.
The only exception is some browsers entity-escaping Unicode characters not representable in the form's target encoding, for example, when the user wants to send the letter ы, but it has no representation in Windows-1252 codepage declared for the form. Other browsers may send the form in the wrong encoding, producing mojibake, or send ?s instead of unrepresentable characters. We are not going to encounter this exception, because we use UTF-8 everywhere and only allow editing text in UTF-8-encoded files.
It's a dead topic and a dead horse, so there's no sense in beating it further.
I am so sorry. I want to clarify this misunderstanding of the relationship between HTML and HTTP because I want to help you make Fossil better, and this may bite you later and hinder your progress. If you really want me to drop this topic, I promise not to reply any further.
(93) By Stephan Beal (stephan) on 2020-05-02 19:02:03 in reply to 92 [link] [source]
I want to clarify this misunderstanding of the relationship between HTML and HTTP because I want to help you make Fossil better
Adding any form of escaping for arbitrary non-binary content only serves to make it more fragile, in that it's more moving parts which can go wrong. We have two separate/independent solutions which require no escaping whatsoever, so there's no reason, other than academic interest, to even consider having to escape any content.
and this may bite you later and hinder your progress.
And i appreciate your feedback and clarifications/corrections, but it is with uncharacteristically absolute confidence that i go on record as predicting that the both the JSON and AJAX approaches will bite us less than any solution involving manually (un)escaping would. You are free to slap this back in my face if that turns out not to be the case, as i will have deserved it.
(94) By Scott Robison (sdr) on 2020-05-02 21:54:09 in reply to 93 [link] [source]
I think what is trying to be communicated is:
Step 1: User clicks link to perform web edit.
Step 2: Fossil creates page with textarea with escaped content.
Step 3: Client browser decodes the escaped content and presents it for editing without any escapes presented to the user.
Step 4: User edits text, clicks submit.
Step 5: Client submits edited text back to the server in an unescaped way, thus there is no need for Fossil to unescape anything.
Fossil server escapes content, browser unescapes content, and it is forever after unescaped at that point.
I've not tried it myself, but that seems to be the breaking point of the communication to me. If I'm wrong or stupid or both, apologies for sticking my nose in.
(95) By Stephan Beal (stephan) on 2020-05-02 21:59:54 in reply to 94 [link] [source]
I think what is trying to be communicated is:
That sounds right to me, but once a solution is found which doesn't require any escaping at all, any statement trying to convince me of the benefits of escaping loses me at "escaping" ;).
(96) By Scott Robison (sdr) on 2020-05-02 22:18:31 in reply to 95 [link] [source]
And I agree with that POV. The only saving grace of the alternative is that it can be done without need for any Javascript, but that is not something that bothers me roughly 1/5th of the way into the 21st century. However, given that it does bother some others, I think the only point that was trying to be made was that there would be no need for fossil to reverse any escapes when receiving the submitted form for checkin.
(111) By Stephan Beal (stephan) on 2020-05-04 10:14:19 in reply to 93 [link] [source]
Yesterday, Stephan Beal said:
And i appreciate your feedback and clarifications/corrections, but it is with uncharacteristically absolute confidence that i go on record as predicting that the both the JSON and AJAX approaches will bite us less than any solution involving manually (un)escaping would. You are free to slap this back in my face if that turns out not to be the case, as i will have deserved it.
A long time ago, Han Solo said:
You said you wanted to be around when I made a mistake, well, this could be it, sweetheart.
And since September, 1969, Scooby Doo's adversaries have always said:
And I would have gotten away with it, too! If it hadn't been for...
Drum roll, please...
"The JSON method" has a fatal flaw, it turns out, and i was lucky enough to have randomly encountered it this early on in a test document:
<script>
/* this is a triple-backtick markdown code block
containing a literal JS script tag */
</script>
When that is embedded in a string in a JS script inside an HTML document (as opposed to a standalone JS file), the HTML parser gets confused and thinks that the opening SCRIPT tag is part of the content. Chaos ensues.
So...
- There goes that.
- AJAX mode only works when the content is in the db, which means it doesn't work for edited/not-yet-saved content.
- After numerous (admittedly not thousands) of tests, the HTML escaping method appears to be working fine.
And now i hand this off to Florian and the anonymous poster to whom i said s/he could slap this back in my face if the JSON form indeed came back and bite me: we both deserve what we're owed.
PS: this isn't yet checked in, but will be once the preview mode is finished.
(112) By anonymous on 2020-05-04 11:13:46 in reply to 111 [link] [source]
When that is embedded in a string in a JS script inside an HTML document (as opposed to a standalone JS file), the HTML parser gets confused and thinks that the opening SCRIPT tag is part of the content. Chaos ensues.
Good catch. I actually thought it was safe to paste valid JSON into a <script> tag; today I learned that's not the case. Thanks for all your testing!
There is a good writeup on the wonders of closing tags in raw text elements. In theory, it should be possible to make a small modification to the JSON encoder to make it escape / slashes with a \ backslash inside string literals (some implementations, e.g. PHP, do that by default). It does not change the JavaScript / JSON meaning of the forward slash (i.e. both '/' == '\/' and JSON.parse('"/"') == JSON.parse('"\/"') are true), but avoids having a literal </script> inside the script element.
(114) By Stephan Beal (stephan) on 2020-05-04 11:31:52 in reply to 112 [link] [source]
I actually thought it was safe to paste valid JSON into a
<script>tag; today I learned that's not the case.
It is until, apparently, you have a SCRIPT tag. It's like when generating script tags programmatically in JS from inside HTML (as opposed to standalone JS), you can't just write the tag like "<script>", you have to instead do something silly like "<"+"script>" to fool the HTML parser. Similarly, when generating PHP code from PHP, it's common to see "<"."?", or similar.
Other tags have been unproblematic in this regard. The script tag is the outlier.
(Doh - an unescaped/un-backticked script tag also breaks the forum preview, unsurprisingly. Be careful to re-escape them when quoting.)
In theory, it should be possible to make a small modification to the JSON encoder to make it escape / slashes with a backslash inside string literals (some implementations, e.g. PHP, do that by default).
i actually asked Douglas Crockford about that long ago and he explained that...
--------------
From: Douglas Crockford <douglas@crockford.com>
To: Stephan Beal <sgbeal@googlemail.com>
Subject: Re: Is escaping of forward slashes required?
It is allowed, not required. It is allowed so that JSON can be safely
embedded in HTML, which can freak out when seeing strings containing
"</". JSON tolerates "<\/" for this reason.
On 4/8/2011 2:09 PM, Stephan Beal wrote:
> Hello, Jsonites,
>
> i'm a bit confused on a small grammatic detail of JSON:
>
> if i'm reading the grammar chart on http://www.json.org/ correctly,
> forward slashes (/) are supposed to be escaped in JSON. However, the
> JSON class provided with my browsers (Chrome and FF, both of which i
> assume are fairly standards/RFC-compliant) do not escape such characters.
>
> Is backslash-escaping forward slashes required? If so, what is the
> justification for it? (i ask because i find it unnecessary and hard to
> look at.)
--------------
Getting that to work here would require that sqlite's json_quote() add those slashes, but i'm hesitant to ask for that because:
- There are bazillions of sqlite3 users, some of whom may rely on the current behaviour (even if only for testing results against literal JSON output which doesn't include the slash).
- Those slashes are, except for embedding in HTML, just ugly noise.
- i'm not sure if that would solve this particular problem. The issue ("unterminated string literal") seems to be triggered initially via the opening tag, not the closing one.
Oh, well. Live and learn.
(113) By Warren Young (wyoung) on 2020-05-04 11:19:43 in reply to 111 [link] [source]
the HTML parser gets confused and thinks that the opening SCRIPT tag is part of the content.
Sounds like it’s insufficiently escaped or quoted, then.
AJAX mode only works when the content is in the db, which means it doesn't work for edited/not-yet-saved content.
Why would it need to?
Since I haven’t tried your branch yet, I’m imagining some functional analog of the forum’s Preview feature. Maybe a “Diff” function?
Regardless, that round-trip can also be Ajax, allowing the unsaved editor contents to be retained client-side.
(115) By Stephan Beal (stephan) on 2020-05-04 11:45:53 in reply to 113 [link] [source]
Sounds like it’s insufficiently escaped or quoted, then.
It's correct per JSON, it's just a semantic incompatibility with JS embedded within HTML. If the JS were in a standalone file it would not be an issue. It's the HTML parser which chokes on it.
It's been so many years since i programmatically constructed script tags in JS that i had forgotten about the "<"+"script>" trick, but we can't reasonably apply that to JSON input. (We "could," but... ugly, ugly hack.)
AJAX mode only works when the content is in the db, which means it doesn't work for edited/not-yet-saved content.
Why would it need to?
For dry-run, preview, and diff modes to work, to pass the just-passed-in content back to the caller. But...
Regardless, that round-trip can also be Ajax, allowing the unsaved editor contents to be retained client-side.
This round-trip may well end up being eliminated via AJAXifying the page, in any case, so that preview (just implemented, not yet checked in) and diff (TODO) can be updated without reloading the whole page. First i'd like to get it working (diff is the only major remaining TODO), and then i'll look at AJAXifying it if there's not too much pushback on going that route. The JS-side infrastructure for doing so is already in place, minus serialization of the POSTed form data to a proper format, but that's trivial to do.
(101.1) By Florian Balmer (florian.balmer) on 2020-05-03 12:04:19 edited from 101.0 in reply to 91 [link] [source]
In any case, escaping is a 100% non-issue now. It's a dead topic and a dead horse, so there's no sense in beating it further.
Hm, yes and no. Correct encoding of data is such a fundamental requirement, for both Fossil and HTTP/HTML in general, that I think any time spent to shed light on this is not wasted.
I try to understand what makes you struggle so much with this. Maybe consider the following HTML fragment to define two textarea elements with initialized contents:
1) `<textarea>&><</textarea>`
2) `<textarea>&><</textarea>` (→ Edit: missing semicolon.)
These two textareas have exactly the same contents, namely &><, and web browsers will also post back exactly the same contents, namely &><, for either of them.
However, case 1) is invalid HTML, due to unescaped special characters. But it will work smoothly, since web browsers are fault-tolerant, and are best-guessing the intended contents of the textarea. However, things will be messed up as soon as dangling </textarea> tags appear, for example, which web browser defensively interpret as closing tags.
Case 2) is the correct method to set the contents of a textarea from HTML.
But since case 1) usually works so well, you may think that instead this is the correct way to set the contents of a textarea from HTML -- and case 2) looks like a strange exception that requires special handling ("unescaping") when posted back.
If there's a non-JSON/non-AJAX solution which avoids all of the content-embedded-in-HTML escaping-related problems we might run into with arbitrary user-supplied content, i'd be happy to hear about it. Escaping user input directly into the raw HTML output, in such a generic context, is simply not an option - we cannot possibly know how/whether to unescape it when saving.
Here you go:
Apply the following patch to initialize the contents of the textarea directly from HTML. Note that the patch only modifies initialization of the textarea, and that no additional work is performed to "unescape" the contents when posted back.
If you have a free minute, no hurry, please try the patch, and show me ANY file (accepted by the /fileedit page) with ANY editing steps that will give a different result from your custom-JSON approach.
Baseline: Fossil [7243aea14a]
Index: src/checkin.c
==================================================================
--- src/checkin.c
+++ src/checkin.c
@@ -3793,11 +3793,11 @@
/******* Content *******/
fp("<h3>File Content</h3>\n");
fp("<textarea name='content' id='fileedit-content' "
"rows='20' cols='80'>");
- fp("Loading...");
+ fp("%h", blob_str(&cimi.fileContent));
fp("</textarea>\n");
/******* Flags/options *******/
fp("<fieldset class='fileedit-options'>"
"<legend>Options</legend><div>"
/* Chrome does not sanely lay out multiple
@@ -3906,11 +3906,11 @@
db_step(&stmt);
zQuoted = db_column_text(&stmt,0);
}
blob_appendf(&endScript,
"/* populate editor form */\n"
- "document.getElementById('fileedit-content')"
+ "//document.getElementById('fileedit-content')"
".value=%s;", zQuoted ? zQuoted : "'';\n");
if(stmt.pStmt){
db_finalize(&stmt);
}
}
I want to clarify this misunderstanding of the relationship between HTML and HTTP because I want to help you make Fossil better, and this may bite you later and hinder your progress.
Yes, of course, JSON encoding needs to be 100% bullet-proof, or the custom-JSON approach won't work ... The HTML-escape approach has been tested in the wild for years!
(102) By Stephan Beal (stephan) on 2020-05-03 13:05:08 in reply to 101.1 [link] [source]
If you have a free minute, no hurry, please try the patch, and show me ANY file (accepted by the /fileedit page) with ANY editing steps that will give a different result from your custom-JSON approach.
i cannot test more than an insignificant fraction of the possibilities of arbitrary user content that, so don't consider any amount of testing on my part to be representative of the weird data users will come up with.
IMO the "onus of proof" lies with those who desperately prefer HTML encoding, and nothing less than an absolutely massive test document base (thousands) of widely-varying files is going to ease my concerns about HTML encoding. My successes with JSON-based apps far exceed my successes with HTML escaping.
Yes, of course, JSON encoding needs to be 100% bullet-proof, or the custom-JSON approach won't work ... The HTML-escape approach has been tested in the wild for years!
And JSON encoding is used millions of times per minute in nearly every conceivable web client since a decade or more. HTML escaping is a non-issue now, as far as i'm concerned. My own, not inconsiderable, experience with using JSON as a data exchange format gives me 100% confidence in its behavior. (Noting that "100%" is not something i say lightly.)
i get that you guys are proving a point, and that's fine, but HTML-escaping arbitrary user content is simply something which makes me lose sleep and stesses me out. It's an absolute no-go for me if it can be avoided, which it can. If the JSON approach, for whatever reason, proves problematic, the AJAX approach is technically even better, in that zero escaping goes on.
Maybe my phobia is not based in reality, but it is a genuine fear, and nothing short of being shown absolutely incontrovertible proof, in the form of test results spanning thousands of disparate file types, is going to make it go away.
We have two great solutions with no conceivable downsides other than a JS dependency (which we already have, anyway - see next paragraph), so why revert to a solution which is a generation or more behind on the evolutionary ladder? It's undisputedly more efficient, but it's also the only one of the 3 current solutions which causes me to literally lose sleep.
If avoiding a JS dependency is the motivation behind sticking with HTML escaping, i consider the risks of escaping to easil be worth that trivial dependency. Fossil is not entirely without JS dependencies (e.g. the timeline's diff-between-nodes feature requires it), and complete independence from JS is simply not practical nowadays in any halfway feature-rich web app. Users who disable JS can use a checkout for this feature, like they always have. To not take advantage of JS in this particular app would unduly castrate it. Its order of operation already requires JS for features other than the JSON step, to update the UI to account for a version change after a non-dry-run save.
(Pardon my brevity - typing on a tablet from the front yard.)
(104) By Florian Balmer (florian.balmer) on 2020-05-03 14:26:47 in reply to 102 [link] [source]
I do not request you to change from JSON to HTML.
I just wanted to clarify your basic misconception that there's any "unescaping" needed by the server, and that this can't be done reliably for certain file types and/or contexts (HTML, source code, etc.).
And I wanted to point out the simplicity and beauty of a <textarea> combined with 3 (in words: three!) HTML-escapes and UTF-8 to cover the full Unicode space, and allow editing of arbitrary text files.
At least you realize that your fear is irrational -- but this also means it can't be defeated with rational arguments.
And, I will remember your sneaky move to ask for a solution, and then turn it down by requesting thousands of tests ... ;-)
(106) By Stephan Beal (stephan) on 2020-05-03 14:32:25 in reply to 104 [link] [source]
And, I will remember your sneaky move to ask for a solution, and then turn it down by requesting thousands of tests ... ;-)
It's not a solution if it's not proven ;). And for what it's worth, i respect that we often disagree - more than once you have convinced me of better solutions.
(107) By Florian Balmer (florian.balmer) on 2020-05-03 14:43:44 in reply to 106 [link] [source]
It's not a solution if it's not proven ;).
I'm just calculating how long it takes to automatically send and evaluate HTTP requests in a for loop from 0x000000 to 0x10FFFF ... ;-)
It's also not a problem for me that my suggestions are not always accepted, I'm well behind the competent and admired Fossil core team (and contributors!) when it comes to this.
(109) By Stephan Beal (stephan) on 2020-05-03 14:46:51 in reply to 107 [link] [source]
I'm well behind the competent and admired Fossil core team (and contributors!) when it comes to this.
Don't be so certain of that! You've proven yourself several times over, as far as i'm concerned. i've been around here a long time (early 2008), but have tended to stay on the "surface" features, whereas you dive right in to features such as changing (for the better) how private branching works. i don't know whether you know this English phrase, but "don't sell yourself short."
(110) By Florian Balmer (florian.balmer) on 2020-05-03 15:02:33 in reply to 109 [link] [source]
... dive right in to features such as .. private branching ...
My contributions are quite superficial and minor here, just a few lines -- really hardly worth mentioning.
Actually, it's quite funny for me to work on this, because my core interests are Unicode with the various representations and encodings, and classic Win32 GUI programming in C with customized message loops and stuff like that ... But Fossil is so good it really deserves attention and time!
(51) By Stephan Beal (stephan) on 2020-05-01 14:21:28 in reply to 37.1 [link] [source]
Mini-milestone: the first dry-run save was just made via the web interface. Pics or it didn't happen.
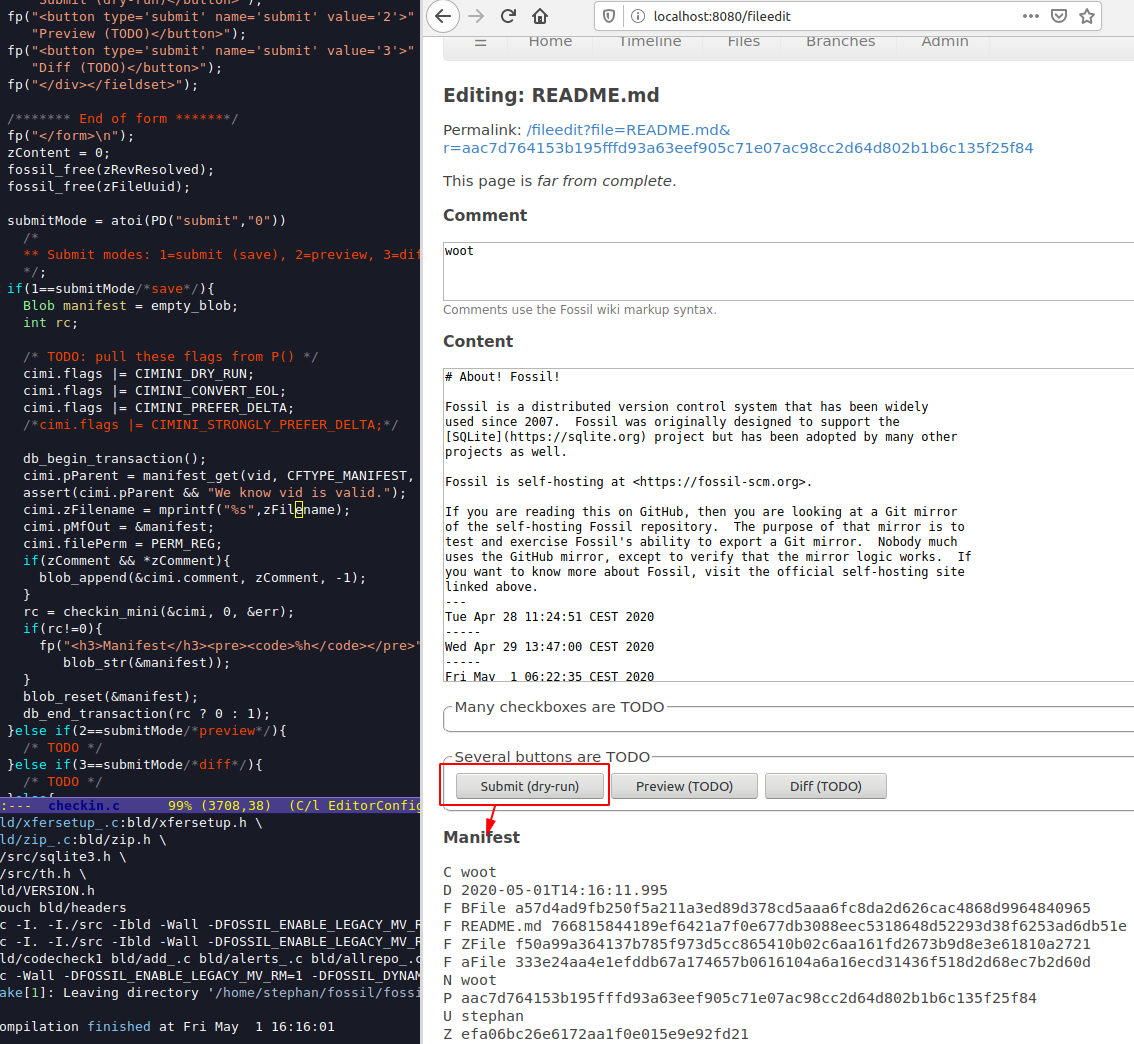{kind=link}
(80.2) By Stephan Beal (stephan) on 2020-05-02 22:12:58 edited from 80.1 in reply to 51 [link] [source]
Mini-milestone: the first dry-run save was just made via the web interface.
Milestone: the world's first-ever non-dry-mode web-based fossil commit:
https://fossil.wanderinghorse.net/screenshots/fossil-fileedit-first-ever-webcommit.png
{kind=link}
(Edit: the copy/paste bug which caused the checkin comment to be duplicated in the N-card field (comment mimetype) has since been fixed.)
(62) By Stephan Beal (stephan) on 2020-05-01 15:47:29 in reply to 1.1 [link] [source]
PS: i really appreciate all of the discussion on this. It's a long overdue feature, IMO, but also one with potential pitfalls which you are all helping to uncover. (The EOL thing would have likely completely passed me by had Florian not mentioned it.)
As soon as i get the various checkboxes/toggles into the web editor (within the next couple of days, in all likelihood), i'll get around to using that mysterious fossil publish feature and push my first-ever previously-private branch. If anyone's really dying to play with it/code review it right now, i can publish it before then. It's only been kept local/private so far because it's still not 100% certain that it will really be a thing, and there seems to be little reason to pollute the main tree with it if it's not. (That said, i'm optimistic about its potential and how it will be received by users.)
(71) By sean (jungleboogie) on 2020-05-01 21:55:34 in reply to 62 [link] [source]
Thank you (and the group) for this contribution to Fossil. I know it's not final, but the idea is great and this discussion is important to have.
(88.1) By Stephan Beal (stephan) on 2020-05-02 22:08:51 edited from 88.0 in reply to 62 [link] [source]
As soon as i get the various checkboxes/toggles into the web editor (within the next couple of days, in all likelihood), i'll get around to using that mysterious fossil publish feature and push my first-ever previously-private branch.
You are all cordially invited to play with the new "web checkin", a.k.a. "mini-checkin", feature:
https://fossil-scm.org/home/timeline?r=checkin-without-checkout
Noting that:
There are currently no links to it anywhere. Use
/fileedit?file=NAME&r=trunkto access it, noting thatr=trunkcan be any supported unambiguous name.It only edits files which match the
fileedit-globwhitelist. You'll need to set that before trying it out. e.g.fossil set fileedit-glob "*.txt,*.md". That config option is in the "project" group and is not versionable, but that's up for discussion. My intent is that on the project's central copy, only admins can change it. (Obviously, a local user can change it at will, but That Way Lies Madness.)It is hard-coded to NOT work in the core fossil repo except in dry-run mode. It will fail fatally if one attempts to checkin in non-dry-run mode. Until it has been fully vetted and verified, it "should" only be used in source trees which one truly doesn't care about. (That said, it "works for me!")
The corresponding CLI command is
test-ci-mini, but it's as yet undecided exactly where (or whether) that belongs in the ecosystem, e.g. as a separate path forcommitwhen it's run outside of a checkout, as a standalone command, or not at all.TODO: preview and diff modes. We have examples of those elsewhere in the tree, so it "should" just be a matter of adapting those to this feature's needs.
TODO: add links to it in "the appropriate places." Anywhere where we have both a checkin version and a filename, we could potentially add a link back to the editor for users who have checkin rights.
The overwhelming majority of the changes are in the bottom half of
checkin.c. There were a few minor incidental related tweaks in other code.
Again, my many thanks to those of you who've contributed to this discussion - it was invaluable to getting this working.
Whew.
Now it's time to take a break and go catch some Netflix or paint some minis.
Edit: web-checkins made "in the wild":
- https://fossil.wanderinghorse.net/r/cwal/info/63556f035b550ab4
- https://fossil.wanderinghorse.net/r/cwal/info/ed727d8cdd920115
The second one could have been avoided if /fileedit had a diff view.
(Never did get around to Netflix or painting.)
(103) By Richard Hipp (drh) on 2020-05-03 13:34:04 in reply to 88.1 [link] [source]
Do you mind if I move the new code out of checkin.c and into a new file, perhaps call fileedit.c?
(105) By Stephan Beal (stephan) on 2020-05-03 14:27:47 in reply to 103 [link] [source]
i actually meant to ask about that. Don't worry about it - i'll handle it.
(108) By Stephan Beal (stephan) on 2020-05-03 14:44:22 in reply to 103 [link] [source]
BTW: the last two replies from you and Florian got moved to separate mail threads again. That was working so well for a week or two, too.
Specifically, gmail split the thread at these two posts:
(116) By Stephan Beal (stephan) on 2020-05-04 13:11:13 in reply to 1.1 [link] [source]
Milestone: Editor preview modes
/fileedit determines which preview mode to use based on an guess at the mimetype from the filename. Anything which is not wiki/markdown/html is considered to be "plain text". The page just got a selection list to override that, in case it guesses wrong for a given file extension, but that's not in the screenshots.
Screenshots:
- Markdown/wiki mode.
- In plain text mode it offers to add line numbers.
- In HTML mode there's a drop-down to select the height (in EMs) of the iframe in which the HTML is embedded. (Populating the iframe was an interesting problem. Thankfully,
encode.chas a base64 encoder, which made it trivial to populate the iframe using a data URL which encodes the whole content in base64.)
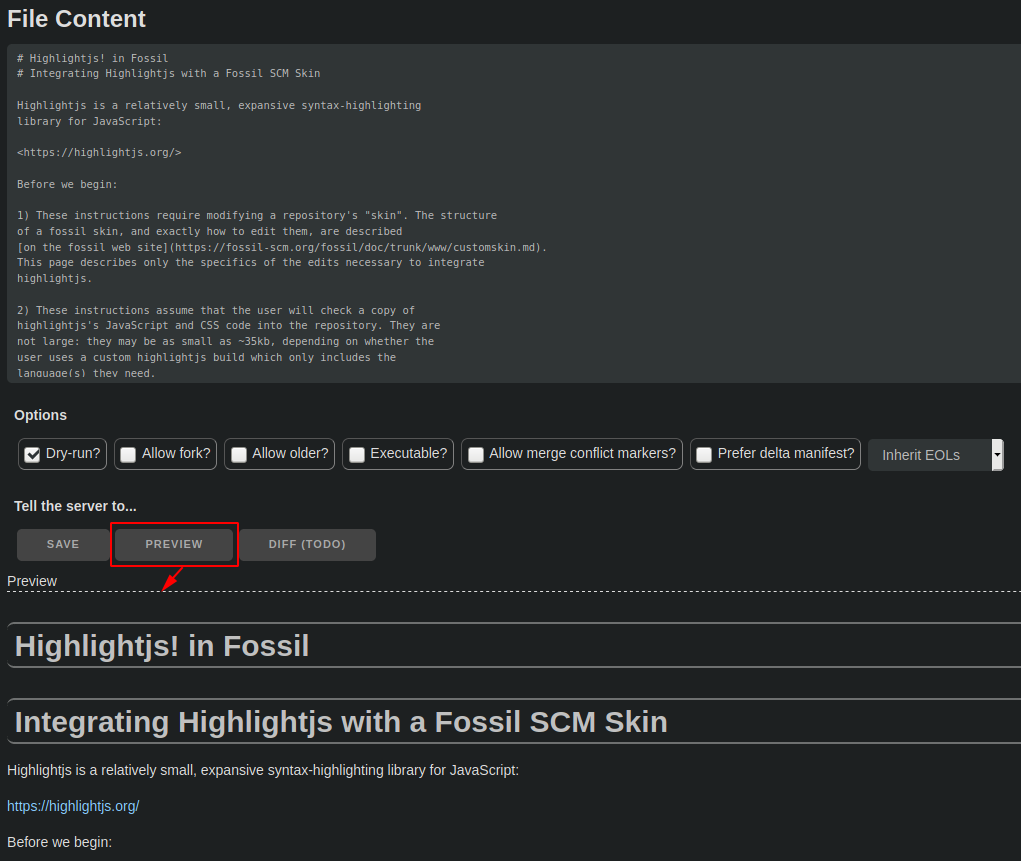{kind=link}
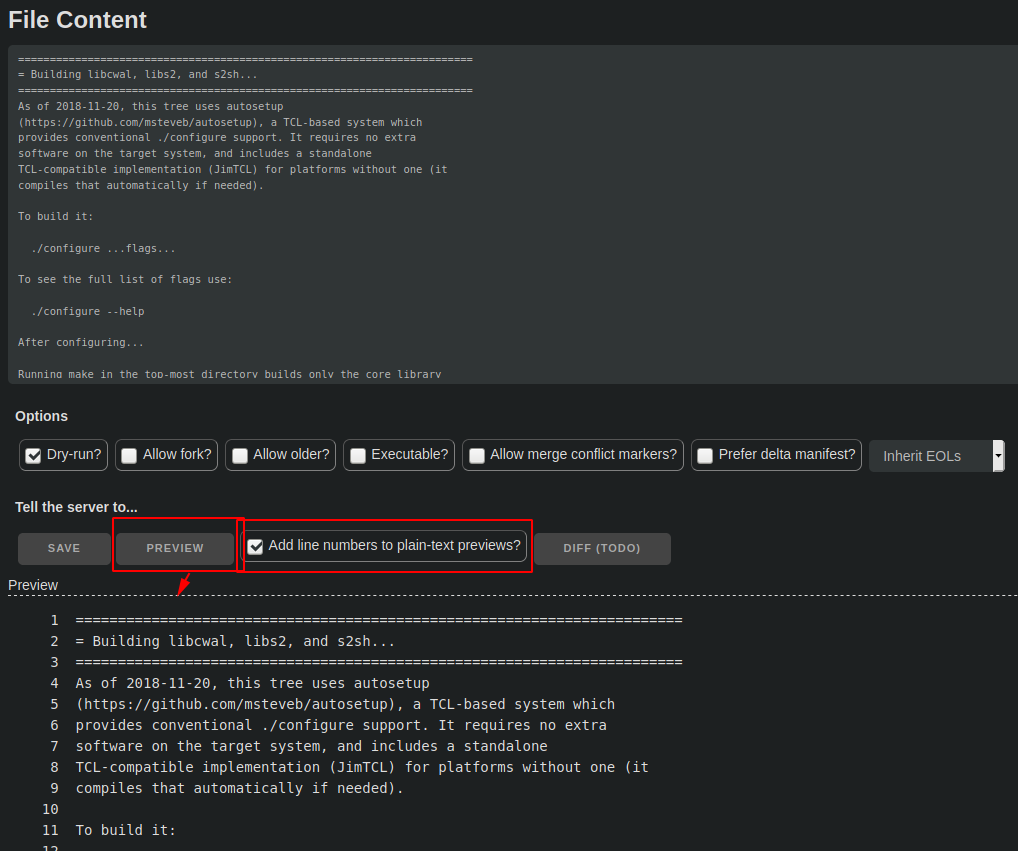{kind=link}
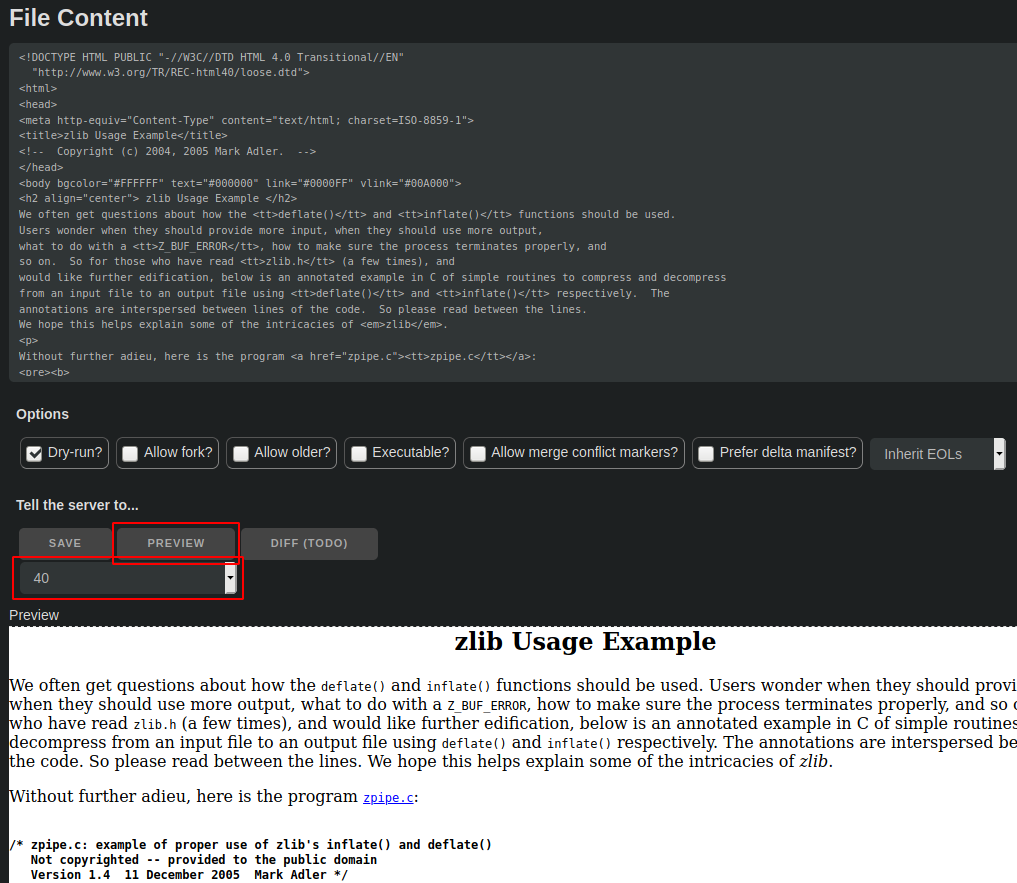{kind=link}
The only major outstanding feature is a diff. We have that in the skin editor, so it "should" be a simple matter of adapting it.
(117) By Joel Dueck (joeld) on 2020-05-04 14:33:39 in reply to 116 [link] [source]
Some suggestions about the “Comment” area (going off your first screenshot, which is the only one I’ve seen that includes it so far):
- Rename it to something like “Commit message” (which is what it is, and less likely to clash with the “Content” heading above the main edit area)
- Move it down so that it sits between “Options” and “Tell the server to…” (and give it the same heading style as those two)
- Make it a required field (if it isn’t already) and mark it as such
I think this better matches the workflow suggested by the page to that of a typical commit (which is what is happening). In a typical commit, you work on your changes and once you’re sure what they are, you summarise them (commit message) and commit. With the commit message at the top I feel like I'm being asked to summarize something before I’ve decided what it is.
(118) By Stephan Beal (stephan) on 2020-05-04 14:44:55 in reply to 117 [link] [source]
Rename it to something like “Commit message”
Good idea - that name was really bugging me!
Move it down so that it sits between “Options” and “Tell the server to…”
Good idea. Those are HTML fieldsets, by the way.
Make it a required field (if it isn’t already) and mark it as such
It is required, but it hasn't yet been marked because i have not yet sat down to figure out how to use the HTML5 form validation features, which i'd very much like to use for the whole form.
If you try to save without a comment it will fail loudly. Do we want a checkbox to override that, and allow an empty message? i'm fundamentally against empty comments, but (A) that's a project-policy-level decision, not mine, and (B) an empty comment is exactly as useful as a dummy message like "." or some such.
Related...
@Everyone:
Should web-based commits be marked differently than normal ones, e.g. via an automatic commit message prefix?
Should they be logged to the admin log?
(120.2) By Stephan Beal (stephan) on 2020-05-04 15:50:04 edited from 120.1 in reply to 118 [link] [source]
Move it down so that it sits between "Options" and "Tell the server to…"
Here you go...
https://fossil.wanderinghorse.net/screenshots/filepage-demo-preview-html2.png
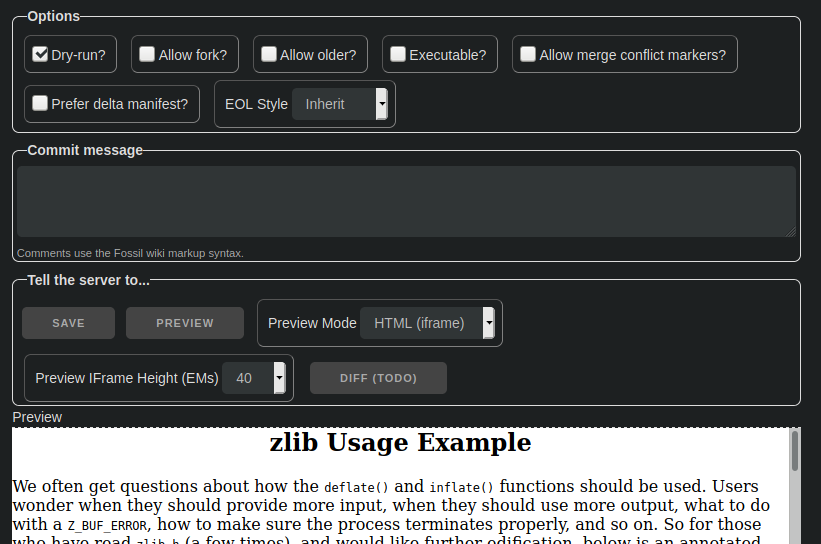{kind=link}
Noting that:
- In most skins, each of those 3 fieldsets would have a border around it. In this skin the border is coincidentally the same color as the page background. (EDIT: screenshot updated to use a visible border color.)
- The selection lists in the "tell the server..." (a new label for that block would be welcomed!) vary depending on the current preview mode. By default the preview mode is determined based on the mimetype (guessed, based on the file extension), falling back to plain text (which isn't basically what's in the editor except for the option to enable line numbers).
- i'm still not happy, in terms of layout, with the commit message being a multi-line field, but if it's only a single line then some weirdo will eventually try to check in two hours' worth of edits and will want to say more than, "minor doc updates."
- The flagging of required fields will be done later via HTML5/CSS.
- Edit: or not. If this field is marked as required that way then we can't even submit for preview mode :/ unless, perhaps, we add JS code to toggle the
requiredattribute on or off depending on which button is pressed :/.
- Edit: or not. If this field is marked as required that way then we can't even submit for preview mode :/ unless, perhaps, we add JS code to toggle the
(121) By Stephan Beal (stephan) on 2020-05-04 17:45:25 in reply to 116 [link] [source]
The only major outstanding feature is a diff. We have that in the skin editor, so it "should" be a simple matter of adapting it.
That was embarrassingly easy.
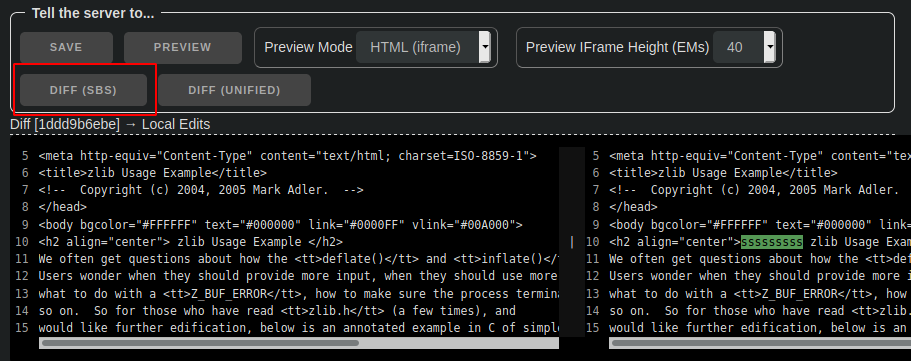{kind=link}
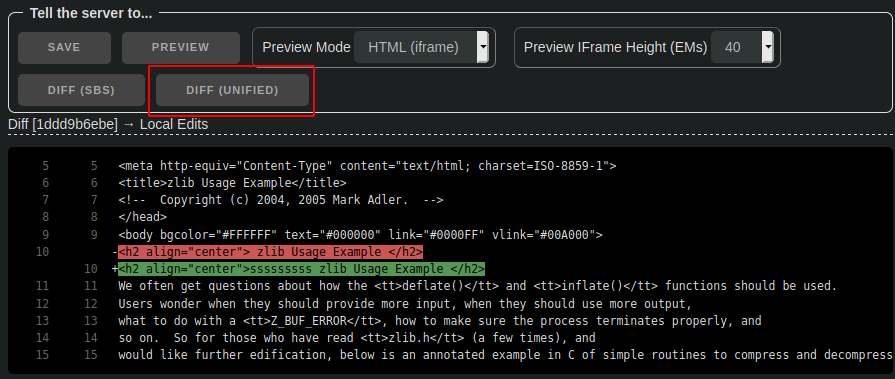{kind=link}
(122.3) By Stephan Beal (stephan) on 2020-05-04 21:32:47 edited from 122.2 in reply to 1.1 [link] [source]
For those who have missed the details scattered among the chatter, the /fileedit page is now "feature complete" (for given values of "feature" and "complete," of course):
https://fossil-scm.org/fossil/timeline?r=checkin-without-checkout
Highlights
- Finally, edit repo-side text files online, limited to files allowed by the site admin(s) by setting the
fileedit-globconfig option.- Visit
/fileedit?file=FILENAME&r=CHECKIN_NAMEto see it in action (requires checkin permissions to use it). Links to it are currently being added to various pages.
- Visit
- Preview modes: wiki/markdown (embedded docs), HTML (in an iframe, so the page and preview don't interfere with each other), and "plain text" (optionally with line numbers). (If your repo has integrated 3rd-party code for syntax highlighting, that will work on previewed markdown pages, provided the code blocks are appropriately tagged.)
- Dry-run mode (on by default - tick the checkbox to turn it off).
- Saving is literally a checkin, so you can edit from the tip of a branch or create a fork from an older version. Like CLI checkins, it will not let you save to a closed leaf, though, and forking requires explicitly ticking a checkbox. However, this "mini-checkin" infrastructure does not itself support tagging or creating branches. There are other pages which already do that.
It could certainly use some "rough treatment" from users who want to try to break it.
The Most Notable Remaining TODOs...
(Disclaimer: the term "collectively decide" obviously implies "with Richard getting the trumping vote." The last thing i want is to introduce a non-trivial feature he's not comfortable with fossil having.)
Collectively decide whether or not to "ajaxify" the page. It currently requires JS, in any case, and the only way around that is to restructure it considerably so that all "real work" gets done before the page is rendered, so that the correct version information can be displayed. (Currently that info gets updated, if needed, by JS code run after the whole page is rendered.)
- Ajaxifying it would mean that the user loads the page once and then runs preview/diff/save over asynchronous "XHR" connections without having to re-load the page.
- That approach would allow us to streamline the UI a bit, using separate in-page tabs for the editor/preview/diff, rather than rendering them in one after another down the page.
- Managing two separate implementations, JS and non-JS, seems unduly painful and unduly necessary, given the increasingly small number of people who actually disable JS. Those users can use a checkout for edits, as our ancestors have done for millennia, since checkouts don't require JS.
- A new branch will be created to get a head start on the ajaxification, with the hope that some of you can pound on the non-ajax version looking for any holes or glaringly missing features. If we decide not to ajaxify, it will be easier to drop that branch than to un-integrate it later.
- IMO, FWIW: let's ajaxify it. Welcome to the 21st century. My heart won't be broken if we don't, though. Y'all decide and let me know which one you want.
Collectively decide the fate of the CLI variant of this feature. It's feature-complete and works, but is currently relegated to a test-only command. The various potential fates include:
- Test-only: it stays where it is now, in a
test-xyzcommand (currentlytest-ci-mini). It's invaluable for testing, as the CLI and web both use the same infrastructure. - A new operating mode for the
commitcommand: if run from outside of a checkout, use this new mode, else behave as it always has. Since commit has never worked outside of a repo, this poses no compatibility issues. - A brand new command. If this is the decision, then the next one is "what's it called?"
- IMO, FWIW: i think it has interesting potential uses, and would prefer to see it integrated as an out-of-checkout operating mode for
commit. Again, though, my heart won't be broken if we relegate it to an unsupported test command. (Two of our users who've expressed an interest will likely be disappointed, though.)
- Test-only: it stays where it is now, in a
Collectively decide which pages to add "edit" links to.
/finfoand/artifactboth have links in my current local copy, and there are probably more interesting places to add them.- Essentially, any place where we have both a checkin version and file name readily handy, we can add a link with ease. If we have to fish out either one of those 2 pieces of info, adding a link becomes more work.
Misc. Decisions:
- Should web commits be logged to the admin log?
- Should web commit comments be clearly marked, e.g. prefixed with "web commit" or some such?
As always, your feedback, patches, opinions, and hard facts are always appreciated. (More often than not, they're also considered. ;)) My one request is that we please try to avoid too much feature creep. Specifically, any features which are already available on other pages (e.g. branching and tagging) are extremely unlikely to get added to this page. (The proposed ability to upload new versions of binary files has not been forgotten or discarded, but it is not on the immediate TODO list.)
This will certainly not be part of the 2.11 release, so there's no particular hurry on any of this.
(123) By Warren Young (wyetr) on 2020-05-04 20:45:02 in reply to 122.1 [source]
the
filename-globconfig option.
fileedit-glob
Links to [/fileedit] are currently being added to various pages.
The main place I'd expect to find it is via /artifact pages served by clicks from /dir.
Saving is literally a checkin
Maybe call the "Save" button "Commit" then, to make it clear what happens when you press it.
Dry-run mode (on by default...
For now only, I hope? Once the feature is stable and ready for merging to trunk, I'd expect dry run to be optional.
Consider the forum, where the "Dry run" option available to forum admins is unchecked by default.
Also consider that the --dry-run/-n option to all Unix commands that take it is off by default.
Ajaxifying it would mean that the user loads the page once and then runs preview/diff/save over asynchronous "XHR" connections without having to re-load the page.
Consider the page's primary audience: people who think editing a file on the back end via a web UI makes sense. Are such people not likely to expect Ajaxy behavior?
Those who think that behavior is wrong likely won't be using the feature at all, regardless of the way it manages its data internally.
Managing two separate implementations, JS and non-JS, seems unduly painful and unduly necessary, given the increasingly small number of people who actually disable JS.
Fossil's a do-ocracy: if someone steps up to maintain a noscript version of the feature, then that's wonderful. If only you are maintaining it, then you get to say "I'm only doing one version."
Welcome to the 21st century.
More like 1981.
Test-only: it stays where it is now
Makes sense to me, but...
A brand new command
I suppose this makes a sort of sense:
$ fossil edit -R ~/museum/my-project.fossil src/foo.c
That could open src/foo.c in $EDITOR; when the editor exits, it checks for a diff, and if there is a change, it opens $EDITOR again to prompt for a commit message.
While workable, it seems too verbose to be widely useful. Unless you're doing it only a few times, it's actually simpler to open the clone locally then use Fossil in its traditional manner.
Another TODO: skinning. The current presentation is a bit rough, at least with the skin I'm testing with at the moment.
(124.1) By Warren Young (wyetr) on 2020-05-04 20:54:39 edited from 124.0 in reply to 123 [link] [source]
$ fossil edit -R ~/museum/my-project.fossil src/foo.c
That reminds me, the r= query parameter should default to trunk for this feature, just as it does for fossil open.
And then in this proposed fossil edit command, it could take an option to give a branch tip name for the edit to apply to.
I suppose it could accept any legal Fossil VERSION string, though that opens the possibility to inadvertent forking. That is, editing a file twice via this URL will create a fork:
https://my-project.example.org/fileedit?file=src/foo.c&r=abcd1234
If the r= parameter is restricted to branch tips, you avoid that problem in the common case, where there is only one public central server.
(127) By Stephan Beal (stephan) on 2020-05-05 00:38:12 in reply to 124.1 [link] [source]
That reminds me, the r= query parameter should default to trunk for this feature, just as it does for fossil open.
i'm not convinced of that. i don't want there to ever be any ambiguity whatsoever about what branch/version one is about to commit to. A closer analog that open is commit. A normal commit implicitly has a parent version, visible via fossil status, but this variant does not, so we need to be more careful. Being explicit is the only solution i'll be happy with in this regard for the web interface. The CLI version does in fact default to the configured main branch, but that's on my to-fix list, after experience with it has made me queasy.
I suppose it could accept any legal Fossil VERSION string, though that opens the possibility to inadvertent forking.
It does, and that's the way it should work. You can't inadvertently fork: there's a checkbox which has to be tapped in order to do so. If you try to save from a non-tip it will fail loudly.
That is, editing a file twice via this URL will create a fork:
That was solved that early on :). When you save in non-dry-run mode, the page updates its version state to the new one, so you can continue editing without risk of a fork (provided nobody else commits in front of you). The version i just checked in does so without requiring JS to update that state (previously the save happened after rendering of the version info, so JS was required to go back and update those DOM elements with the new state).
If you try to save immediately a second time, you'll be at the proper tip but get a "file has not changed" error - this variant does not allow no-op commits.
If the r= parameter is restricted to branch tips, you avoid that problem in the common case, where there is only one public central serve
Restricting it to tips would indeed cover the common case but would be unduly castrated. There's no reason to restrict users from forking or editing non-leaf versions, so long as the editor doesn't inadvertently do it for them. Also, the /dir paths to files would, more often than not, not be able to have an edit link because those files are normally not in the tip of their branch. (Discovered that after adding the edit links there.)
(125) By Stephan Beal (stephan) on 2020-05-04 21:59:14 in reply to 123 [link] [source]
fileedit-glob
Correct and corrected!
The main place I'd expect to find it is via /artifact pages served by clicks from /dir.
That was the first page to get it :)
Maybe call the "Save" button "Commit" then, to make it clear what happens when you press it.
Good idea. Will do momentarily.
For now only, I hope? Once the feature is stable and ready for merging to trunk, I'd expect dry run to be optional.
It's off primarily to avoid "oopsies," at least while the feature is in its infancy. We can of course default it to off at the flip of a bit. Currently, if a user disables it and saves, the page flips it back on "just in case." With the ajaxification that would go away, though.
Those who think that behavior is wrong likely won't be using the feature at all, regardless of the way it manages its data internally.
That sounds very likely.
Fossil's a do-ocracy:
That's my new favorite word.
if someone steps up to maintain a noscript version of the feature, then that's wonderful. If only you are maintaining it, then you get to say "I'm only doing one version."
i wasn't gonna put it quite like that, but was going to stubbornly resist a nojs version if we also have an ajax version. i don't mind maintaining either one, but don't want to see fossil have both :/. Ajax "would be cool," but i won't lose sleep if nojs is the way The Collective and our Benevolent Dictator decide is best. Either way, i'm going to ajaxify it so that we have a basis for comparison, if nothing else.
More like 1981.
Long Live Emacs.
I suppose this makes a sort of sense:
$ fossil edit -R ~/museum/my-project.fossil src/foo.cThat could open src/foo.c in $EDITOR; when the editor exits, it checks for a diff, and if there is a change, it opens $EDITOR again to prompt for a commit message.
That's a bit out of the current code's scope/features, but not terribly far. That sounds like a feature for another do-ocracy member, though ;). My main interest is the scriptability/non-interactivity:
(From outside of a checkout.)
fossil commit ~/tmp/foo.js --as js/foo.js -m 'blah' ...
As one user mentioned, this might be an interesting way to archive logs and similar backups.
i have literally never once used (on purpose) the edit-during-commit feature in any SCM. That just feels unnatural to me. i realize, however, that it has a long and glorious history.
Another TODO: skinning. The current presentation is a bit rough, at least with the skin I'm testing with at the moment.
Oh, you want a pretty UI. UIs i can do, but pretty UIs are another thing entirely!
It looks nice with my skin :), but mine has admittedly been tweaked considerably over the past 6 months. If you can post some screenshots, or tell me which built-in you're using, i can take a couple whacks at it. The styling, with the exception of the textarea row/column count and iframe height, are all done with CSS: search src/default_css.txt for fileedit and work your way down from there. i've only tested it with FF, and Chrome/Firefox often differ notably for the same styling. Checking it in Chrome is on my TODO list.
In any case, the styling will probably get a notable overhaul when the UI is tabbified (which will be the step after ajaxification).
Work on the ajaxification is currently underway but i'm doing some refactoring in prep for that and don't expect to have a useful ajax demo for at least a couple of days. The relatively feature-rich JS fetch() work-alike, for generic GET/POST work, is currently only 53 lines and 1.5kb, and seems unlikely to grow appreciably.
Thanks for the feedback!
(126) By Stephan Beal (stephan) on 2020-05-05 00:28:30 in reply to 125 [link] [source]
Ajax "would be cool," but i won't lose sleep if nojs is the way The Collective and our Benevolent Dictator decide is best. Either way, i'm going to ajaxify it so that we have a basis for comparison, if nothing else.
FWIW, this checkin was refactored to allow the editor to work without any JS.
Now that that's done, it's time to ajaxify it. (It does load some JS but doesn't currently use it - it's part of the next step.)
(128) By Stephan Beal (stephan) on 2020-05-05 07:04:41 in reply to 125 [link] [source]
Work on the ajaxification is currently underway but i'm doing some refactoring in prep for that and don't expect to have a useful ajax demo for at least a couple of days.
Couldn't sleep... as of the commit a few moment ago, /fileedit is 100% ajaxified:
https://fossil-scm.org/fossil/timeline?r=fileedit-ajaxify
The speed difference is tremendous. All that remains now is cleanup, refinement, and prettification.
@Richard: i have not yet started on a more generic C-side model for this, other than to check the generic transport/ajax layer into the builtin files and introduce window.fossil as a namespace for common JS-side bits (via src/fossil*.js and a bootstrapping of that via style.c). Those parts are working well with /filepage's 4 ajax routes, and those respond with several different data types:
- fetch content:
application/octet-stream - diff, preview:
text/html - commit:
application/json, which includes the new version number and the full manifest
It can also handle binary data, but it has not yet been used for that.
All of them report errors by sending back a JSON payload with {"error":"..."}, and the ajax layer looks for that and reports it by setting the message as the innerText of an app-defined HTML element (if set, else it just reports to the dev console).
The relatively feature-rich JS fetch() work-alike, for generic GET/POST work, is currently only 53 lines and 1.5kb, and seems unlikely to grow appreciably.
Okay, it grew to 86 lines and 2.5kb, unminified (1.7k minified).
(130) By Florian Balmer (florian.balmer) on 2020-05-05 11:10:26 in reply to 128 [link] [source]
... Han Solo said: ...
It's funny you're quoting Star Wars, since your coding style looks like it was inspired by another Star Wars character ☺ (scroll down to the first point):
Good catch about <script>, indeed! I knew it, only you would be clever enough to find a flaw (the only flaw?) in your JSON approach. I really didn't think of this, despite running into something similar, recently:
fetch content:
application/octet-stream
With text/plain; charset=utf-8 you get HTTP reply compression for free! (Since only valid UTF-8 text files are allowed by the /fileedit page.)
... prefer to see it integrated as an out-of-checkout operating mode for
commit.
I still think this is not a good idea, because that's not how the -R switch works:
Fossil commands show identical behavior, and offer identical options, whether used from a check-out, or launched with the -R switch.
The test-ci-mini command supports different options compared to commit, and adding the -R switch is by no means a 1:1 replacement for an open check-out, but the similarities seem outright confusing.
To make things easier to maintain, document and use, I prefer to keep the new features untangled from commit. This won't hurt anybody, and won't break anything. Untangling the commands at a later stage, for whatever reason, however, may then break many scripts.
Regarding the name: what about fast-commit (fci, i.e. if a check-out with too many files is considered "slow"), or direct-commit (dci, i.e. bypassing the check-out)?
(131) By Stephan Beal (stephan) on 2020-05-05 11:44:49 in reply to 130 [link] [source]
It's funny you're quoting Star Wars, since your coding style looks like it was inspired by another Star Wars character ☺ (scroll down to the first point):
Lifesavers, Yoda conditions are. My bacon more than once they've saved! They take getting used to, but once you're used to them, putting the non-const on the left of a comparison just feels barbaric and needlessly risky.
a flaw (the only flaw?) in your JSON approach.
i do really think it is the only one, but it's absolutely fatal and has no reasonably workaround. (This is one, but it's tremendously ugly.)
I really didn't think of this, despite running into something similar, recently:
Precisely like that one.
With text/plain; charset=utf-8 you get HTTP reply compression for free! (Since only valid UTF-8 text files are allowed by the /fileedit page.)
It only serves with octet-stream if fossil can't figure out a mime type using mimetype_from_name() (so file-extension based). Eventually it "should" be able to server at least a subset of binaries, like images, and allow those to be updated. (We could do that with drag and drop of an image directly into the page.)
Now that you mention it, though... i'll change that to do a fallback check for binary, and only use octet-stream for binaries, falling back to text/plain for the others.
I still think this [making it part of the checkin command] is not a good idea,
i really don't have a strong opinion, either way. You guys can figure it out and we'll go that way.
As far as a name goes... i don't like any i've seen or come up with so far :/, with "mini-commit" or "mini-checkin" being the ones which bother me the least so far. Maybe we can just start numbering them. fossil command-145 .... Or naming them after pop culture icons: fossil babyyoda ... Or name them after the date of their first implementation: fossil 20200501 (or whenever it was).
(132) By Florian Balmer (florian.balmer) on 2020-05-05 11:50:10 in reply to 131 [link] [source]
What about:
fossil stephan
Or, localized to Swiss German:
fossil steffufossil stifu
;-)
(133) By Stephan Beal (stephan) on 2020-05-05 12:08:42 in reply to 132 [link] [source]
Let's find a good combination of all of our names. Something along the lines of...
fossil waristeflo
fossil flowarist
Or...
fossil cwain # Command Without An Interesting Name
fossil cwain # Checkin Without An Interesting Name
There are ancient precedents for those approaches. awk, TWAIN scanner drivers, ...
fossil cinc # CINC Is Not Commit
fossil ootc # Out-of-Tree Commit
fossil noncommittal # meh - too long
fossil cannot-commit
fossil clc # CLC is Like Commit (a-la the ELM mail reader)
# CLC is Light-Commit
fossil clic # CLiC ^^^^
fossil cömmit # (look closely)
fossil comet # as a near-homonym of commit
fossil komm mit # apropos German
Or not. That's also a detail y'all can figure out. None of them really speak to me, except maybe "cinc" and "clic," but i probably wouldn't recommend either of those. comet's not too bad, but doesn't really fit the existing naming scheme.
Naming things is hard.
(135) By graham on 2020-05-05 13:40:21 in reply to 133 [link] [source]
fossil yacc # Yet another check-in command :-)
(136) By anonymous on 2020-05-05 13:47:58 in reply to 130 [link] [source]
Regarding the name: what about fast-commit (fci, i.e. if a check-out with too many files is considered "slow"), or direct-commit (dci, i.e. bypassing the check-out)?
How about 'fossil fileedit' to be consistent, or 'fossil revise'?
I'm not sure if this needs to be a CLI command. After all, once at command line and dealing with files, then as well can do proper checkout and commit.
This command does not add a file if it's not managed yet, otherwise 'fossil save' would be closer to what it's doing.
(137) By Stephan Beal (stephan) on 2020-05-05 17:59:52 in reply to 136 [link] [source]
How about 'fossil fileedit' to be consistent
That superficially makes sense, but the CLI side of it has nothing at all to do with editing - it takes what you edited in emacs and just stuffs it into the db.
or 'fossil revise'?
To me "revise" has a similar implication, as if the feature is somehow empowering edits or revisions, which it's not. The web version certainly does, but not the CLI version.
I'm not sure if this needs to be a CLI command. After all, once at command line and dealing with files, then as well can do proper checkout and commit.
Try telling that to our poster who is so excited about this option ;).
The CLI version really only exists because it's used for the rapid testing/development of the UI-agnostic infrastructure-level bits. It's just faster to develop those parts that way.
This command does not add a file if it's not managed yet, otherwise 'fossil save' would be closer to what it's doing.
That's one difference in the CLI version: it optionally can add a new file, but it does not do so by default because it would be way too easy to accidentally add the same file multiple times with differently-cased named. Thus it requires an explicit flag to allow a new file to be added. Most fossil repos have case-sensitive names, so "x/y/z" and "X/y/z" are two different files... until they're checked out on a case-insensitive filesystem, at which point chaos ensues.
The web interface doesn't offer that because it doesn't even remotely fit in to the current web-side workflow. It wouldn't be impossible to do, but it would require that the user provide precisely the right filename, including case, to avoid madness such as uploading a file as "x/y/z.txt" when "X/Y/z.TXT" was intended. It seems safer to punt on that problem by simply not implementing the feature (especially seeing as it's never yet been needed).
(140) By anonymous on 2020-05-07 20:19:28 in reply to 137 [link] [source]
Hmmm... just a side note, begin:{
somehow your response above rings more like a rebuttal. Which it needs not to be. After all, you did ask for suggestions. It's no trivia contest whith a right answer to guess.
You're sure free to name the command the way you'd like without the need to justify why the suggested choices are not fitting.
Brainstorming does not have to become a zero-sum game... unless you're selling the naming rights :)
}:end
(141) By Stephan Beal (stephan) on 2020-05-07 20:29:26 in reply to 140 [link] [source]
somehow your response above rings more like a rebuttal.
It was an explicit acknowledgement of your suggestions and an explanation of why i don't agree with the terms "edit" and "revise" for this context.
You're sure free to name the command the way you'd like without the need to justify why the suggested choices are not fitting.
Explaining why those two terms don't seem appropriate to me seemed a better/more appropriate/friendlier option than silently disregarding the suggestion or simply saying, "nope."
(134.1) By Stephan Beal (stephan) on 2020-05-05 12:28:09 edited from 134.0 in reply to 123 [link] [source]
Another TODO: skinning. The current presentation is a bit rough, at least with the skin I'm testing with at the moment.
Make sure you reload the page a couple of times to get the latest CSS. The first 2 or 3 hits on this other machine, with the default skin, left me thinking, "man, he wasn't kidding!" until the CSS finally refreshed. (Firefox sometimes ignores the "disable cache" checkbox in the dev tools.)
That's not to say it will look great once the CSS kicks in, but it shouldn't look like an absolute train wreck.
(154.1) By Stephan Beal (stephan) on 2020-05-17 05:02:51 edited from 154.0 in reply to 123 [link] [source]
Another TODO: skinning. The current presentation is a bit rough, at least with the skin I'm testing with at the moment.
Much has changed since then. (My goodness, has it already been two weeks?) i just went through it and did a sanity check with all of the built-in skins and after a couple minor style patches, with the exception of Bootstrap, it actually looks fairly decent (one skin shifts it down under a floating menu, but that's the worst of it). Bootstrap is a tiny bit broken, in that it doesn't use $stylesheet_url, and requires this trivial patch:
https://fossil-scm.org/fossil/info/100c67fa507b44ad
with that, Bootstrap loads the page-specific CSS and also looks pretty decent, too.
Some skins do really weird things like setting the height of all textareas to 32px, or the "display" of LABEL tags to "block", which caused /fileedit all sorts of grief, but it now overrides those oddities, as they're discovered, in its page-specific CSS.
(129) By anonymous on 2020-05-05 07:44:55 in reply to 122.3 [link] [source]
CLI: +1
I will definately make use of this if available...
(138) By Stephan Beal (stephan) on 2020-05-05 22:38:07 in reply to 1.1 [link] [source]
Usability question:
i've deployed the tabified/ajaxified /fileedit on my most active repo and am uncertain about one particular usability aspect, and am looking for opinions...
In the current configuration, if the preview mode is especially long, it grows the page as needed, leading to the page having scrollbars, but not the preview wrapper:
https://fossil.wanderinghorse.net/screenshots/filepage-demo-preview-tab-noscroll.png
{kind=link}
Note the lack of scrollbars around the preview (the browser window has them, but they're outside of the screenshot).
It would also be possible to cap the max height of the preview wrapper, such that if the preview grows beyond that height, the wrapper gets scrollbars:
https://fossil.wanderinghorse.net/screenshots/filepage-demo-preview-tab-scroll.png
{kind=link}
Note the scrollbars on the preview element, marked in red.
Which is more intuitive/usable?
It "could" be made configurable with a toggle but that seems like unnecessary overkill. It could be configured via client-side CSS overrides with something like:
#fileedit-tab-preview-wrapper {
max-height: 50em;
overflow: auto;
}
(139) By Stephan Beal (stephan) on 2020-05-07 01:37:57 in reply to 1.1 [link] [source]
In my very humble opinion, the newly-ajaxified-and-tabbed /fileedit page is now "ready," not for trunk (that's post-2.11), but for use by anyone unafraid to use a branch version on a daily basis:
Highlights from the past couple of days:
- Its required URL arguments differ from the first announcement:
filename=the/file&checkin=version, for consistency with the annotate/blame pages, and possibly others. There are links to/fileediton a couple other pages, namely the file history list and/artifactwhen it's operating on a file. - A complete UI overhaul. The tabbed interface is much friendlier than the initial draft.
- A spiffy approach to confirming actions, such as the "discard/reload edits" button: tap it once to enter a confirmation mode where it counts down from 3. If tapped again in that time, it performs the operation, else it times out and does not do anything. This can easily be added to any button or button-like widget.
- Basic font size selector for the editor.
- Two options for previewing HTML content: iframe (for full-fledged documents) and "inline", for document fragments which are intended to be wrapped in the larger site skin.
Please post any bugs/requests/feedback in this thread or contact me directly if you prefer.
Enjoy!
(142) By Warren Young (wyoung) on 2020-05-08 09:54:10 in reply to 139 [link] [source]
now "ready,"
It's installed and enabled for battle-testing on two repos under tangentsoft.com.
There's some kind of JS caching problem with the current version. Twice now I've seen this error at the top of the UI:
2020-05-08 09:38:01 UTC: Exception: TypeError: self.e is undefined
Clearing the browser cache and reloading helped the first time, but it came back again and I needed to do a force reload. (Cmd-Shift-R in macOS Firefox.)
It appears that the JS in question is not being served with a cache-busting query parameter based on a commit ID. E.g.:
/builtin/fossil.page.fileedit.js?ver=abcd1234
Done that way, every time the source code changes, the version changes, so the browser is forced to fetch it again.
There should be built-in code within Fossil already to generate such things, which you could reuse. It's used for style.css, for instance.
filename=the/file&checkin=version, for consistency with the annotate/blame pages, and possibly others.
...But now inconsistent with /file, /raw, and /artifact, which use ci as the version parameter.
Rather than change it back, how about follow those same routes' examples and add short aliases, ci and fn?
The tabbed interface is much friendlier than the initial draft.
Yes. Still some skinning work needed, but that can be done later, even after a merge to trunk.
For instance, with the default skin, I think the tabs should have a light gray background to match the main button bar. The selected tab might have a slightly paler gray to set it off from the others.
A spiffy approach to confirming actions
That sounds like it could be accidentally triggered by a double-click.
Anything wrong with just using confirm()?
Basic font size selector for the editor.
The perceived need for this may be an indication that the skin should be changed to just use a larger monospace font. It's one of the changes I usually make to the stock skins, but that may just be my eyeglasses prescription talking.
(143) By Warren Young (wyoung) on 2020-05-08 09:58:47 in reply to 142 [link] [source]
It's not caching: it just happened to me again on changing the "checkin" parameter from the hash it generates by default to "trunk."
That said, it should also do cache-busting.
(144) By Stephan Beal (stephan) on 2020-05-08 12:04:10 in reply to 142 [link] [source]
There's some kind of JS caching problem with the current version. Twice now I've seen this error at the top of the UI:
That happens to me from time to time as well on FF, though sometimes with a different errors. It's something related to caching, but doesn't seem to be caching, exactly.
It appears that the JS in question is not being served with a cache-busting query parameter based on a commit ID. E.g.:
i will definitely add that.
But now inconsistent with /file, /raw, and /artifact, which use ci as the version parameter. Rather than change it back, how about follow those same routes' examples and add short aliases, ci and fn?
i don't mind offering two names, and did that for a few commits, but would rather see us settle on a common convention (my preference being full words). i'll add ci/fn as "undocumented aliases", in any case. We have at least one page (finfo?) which uses "m" (manifest) instead of "ci".
For instance, with the default skin, I think the tabs should have a light gray background to match the main button bar.
Rather than mess with the colors, since my sites all use a dark skin, i opted to change the text instead of the background. If we use any particular color scheme it's going to clash with at least one of the builtin skins. i tried to use CSS's "invert" filter for that effect, but that apparently cannot invert inherited colors - it only seems to work if the colors are set directly on the element.
That sounds like it could be accidentally triggered by a double-click.
It can, but buttons are not for double-clicking, and anyone double-clicking a button deserves what they get. i spend a good 10 hours a decade ago trying to get JS to reliably catch/disable double-clicks on buttons, in order to try to fix broken user behaviour, and never got it working.
Anything wrong with just using confirm()?
confirm and alert are nono's: if a page shows dialogs more than some number times (4 for firefox), the browser offers a checkbox to disable them entirely on that page. This particular confirmation is not critical - it's simply confirming that the user doesn't want to lose their current edits. If they double-click the button... it's their own fault, seriously. That's a bad, bad habit.
The perceived need for this [font size selector] may be an indication that the skin should be changed to just use a larger monospace font.
It was added because i had trouble reading with the default font size in one of the skins i tried it on. A person editing files may have zero control over the skin's font size and the person who does control that might have excellent 25-year-old eyes and not want a 28pt font there.
(145) By Stephan Beal (stephan) on 2020-05-08 12:50:30 in reply to 142 [link] [source]
Just checked in:
- fn/ci are accepted as (undocumented) aliases for filename/checkin.
style_emit_script_builtin()adds a cache-buster (a prefix of the MD5 of the builtin file's contents) when generating "src=..." attributes:
<script src='/cgi-bin/ftest/builtin/fossil.bootstrap.js?cache=6d6d4595'></script>
<script src='/cgi-bin/ftest/builtin/fossil.fetch.js?cache=86ca4090'></script>
...
This new version has been sanity-checked on my hoster.
(146) By Warren Young (wyoung) on 2020-05-08 13:13:32 in reply to 145 [link] [source]
adds a cache-buster
Thank you. Alas, the symptom remains.
It's easy to trigger: just change the checkin parameter back and forth a few times. The bug will bite eventually.
(147) By Stephan Beal (stephan) on 2020-05-08 13:53:29 in reply to 146 [link] [source]
It's easy to trigger: just change the checkin parameter back and forth a few times. The bug will bite eventually.
And it's not specific to this tree - it happens to me at least once or twice a day in FF on an HTML/JS hobby project of mine.
i suspect, but don't know for certain, that this is related to FF's frustrating behaviour of preferring to reset form fields to their previous values when a page is reloaded (see also). That has the potential for side-effects vis-a-vis event handlers. i have yet to see this problem on Chrome in my other project, and will switch to Chrome for a while for this one to see if it can be spotted there.
All of the fossil-related JS which runs app-level logic, as opposed to simply defining new functions, is deferred until a window.load event fires, so the intermittent startup-time errors like "X.Y is undefined" are "impossible," in that if they pop up at all, they need to do so 100% of the time. All startup-time async activity (loading the content) is deferred until literally the last thing on the page (and only if the page successfully renders), so that part cannot be triggering any as-yet-uninitialized JS code.
It's curious, certainly.
(148.1) By Stephan Beal (stephan) on 2020-05-08 14:18:31 edited from 148.0 in reply to 147 [link] [source]
It's curious, certainly.
After triggering it in Chrome i believe i have found the culprit: a race between the the onload event and the initial loading of the content (which happened outside of onload). The tip version delays the content load until window.load, and that seems to have resolved it. (Edit: since that change i've been unable to trigger this effect, and have confirmed that window.load event handlers are, in HTML5, triggered in the order they are registered, so the order is still well-defined vis a vis the other init code which waits for window.load.)
(149) By Stephan Beal (stephan) on 2020-05-09 12:40:52 in reply to 139 [link] [source]
Highlights from the past couple of days:
- Added selection list for commit comment mime type (N-card): fossil, markdown, plain text.
- Added toggle to switch between single- and multi-line comment editing modes, noting that switching from multi- to single-line will strip all newlines (this is how JS handles assigning a value with newlines to an
input[type=text]field (again what learned)).
(150) By Richard Hipp (drh) on 2020-05-09 13:25:07 in reply to 149 [link] [source]
Last time I checked, the N-card is not used for check-in comments. The current timeline display assumes text/x-fossil-wiki everywhere, regardless of the N-card. Has that changed?
I know the documentation says that the N-card should determine the mimetype of the check-in comment, and I think I put that in with the intention of actually making it do so, but I don't think anybody ever got around to making that happen.
(151) By Stephan Beal (stephan) on 2020-05-09 13:48:33 in reply to 150 [link] [source]
Last time I checked, the N-card is not used for check-in comments. The current timeline display assumes text/x-fossil-wiki everywhere, regardless of the N-card. Has that changed?
That's also my understanding, but i was working from the manifest format docs, which allow an N-card. We can hide that part of the UI until/unless honoring of the N-card is ever implemented.
(152.1) By Stephan Beal (stephan) on 2020-05-10 08:56:36 edited from 152.0 in reply to 151 [link] [source]
Last time I checked, the N-card is not used for check-in comments. The current timeline display assumes text/x-fossil-wiki everywhere, regardless of the N-card. Has that changed?
That's also my understanding, but i was working from the manifest format docs, which allow an N-card. We can hide that part of the UI until/unless honoring of the N-card is ever implemented.
That UI element is now removed, but an alternative implementation might be to keep it visible but disabled, in the hopes that that might prompt someone to implement the multi-format comment rendering ;).
And in related news:
Today's new feature: auto-preview. The tabbed interface now supports firing events immediately before and after a tab is switched to, so that an event listener can do lazy loading/auto-refresh of any given tab's contents. So... when switching to the preview tab, the preview will, by default, be automatically refreshed. There's a checkbox to disable this, in case a user wants to frequently switch back and forth without waiting on the server each time. The "manual" preview refresh button is still there and works as before.
(153.1) By Stephan Beal (stephan) on 2020-05-11 12:12:32 edited from 153.0 in reply to 152.1 [link] [source]
Today's new feature:
...
/filepage no longer requires URL arguments: it has selection lists for the leaf checkins and their files:
https://fossil.wanderinghorse.net/screenshots/fileedit-file-selector-demo.png
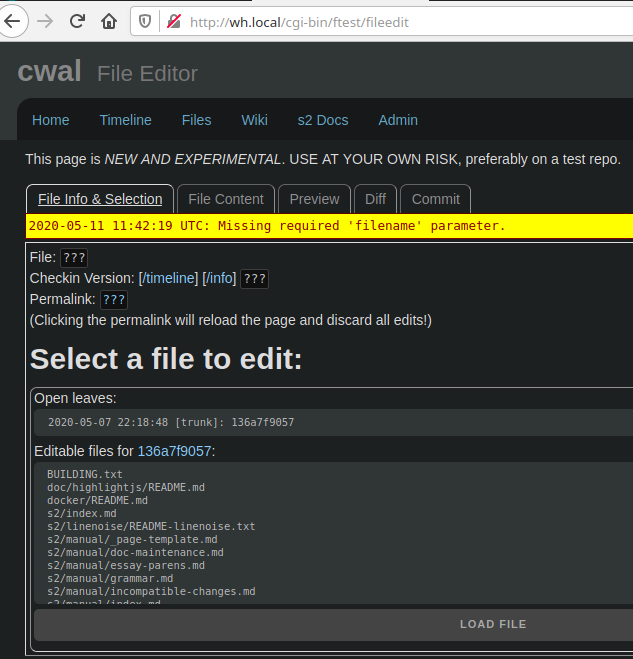{kind=link}
It restricts the selection list of checkins to open leaves, noting that (A) obviously, any parallel activity in the repo may invalidate that list and (B) the core fossil repo has 143(!) open leaves, most stale, the oldest from 2009-01-30. (i'll go through and close old ones which can unambiguously be closed - it looks like some are intentionally left open for timeline tests.)
Edit: it restricts the list of files to those editable by the current user and whitelist.